
Kompletny przewodnik po kanonicznych adresach URL
Opublikowany: 2022-03-17Gdy treść, która jest dokładnie taka sama lub prawie taka sama, pojawia się na co najmniej dwóch stronach, nazywamy to zduplikowaną treścią. Największym problemem związanym z duplikatami treści jest to, że wyszukiwarki nie wiedzą, którą wersję treści indeksować lub pokazywać w wynikach wyszukiwania. Trudno jest również ustalić, gdzie kierować wskaźniki linków, takie jak autorytet i zaufanie. A gdy inne witryny muszą wybierać między zduplikowanymi wersjami treści, do których prowadzą linki, można wybrać dowolny z wielu linków, co osłabia ich wartość. W tym miejscu pojawiają się kanoniczne adresy URL. Służą one do usuwania problemów związanych z powielonymi treściami, co może poprawić pozycję w rankingu wyszukiwarek.
Co to są kanoniczne adresy URL?
Kanoniczny adres URL, do którego odwołuje się tag HTML rel="canonical" , jest używany przez wyszukiwarki do znalezienia głównej wersji treści, gdy istnieje wiele wersji strony w tej samej witrynie lub w różnych witrynach.
Załóżmy na przykład, że publikujesz post na blogu we własnej witrynie internetowej. Następnie chcesz również opublikować ten wpis na blogu na swoich kontach LinkedIn i Medium. Dzięki tagowi kanonicznemu możesz poinformować wyszukiwarki, że chociaż ten sam post na blogu znajduje się w wielu witrynach, to ten w Twojej witrynie jest wersją główną, czyli tą, która powinna pojawiać się w wynikach wyszukiwania.
I pamiętaj, że z technicznego punktu widzenia kanoniczny adres URL nie jest tak naprawdę adresem URL — jest raczej tagiem dołączonym do adresu URL, aby przekazać jego znaczenie wyszukiwarkom. Jeśli rzeczywisty adres URL wygląda tak: http://example.com/blogpost , wersja kanoniczna wyglądałaby tak:

Nie możesz przejść do tego kanonicznego adresu URL, tak jak do głównego adresu URL. Zamiast tego, wersja kanonizowana jest umieszczana w kodzie HTML strony (lub przypisywana do strony za pomocą wtyczki).
Dlaczego powinieneś używać kanonicznych adresów URL
Kanonizacja adresu URL informuje wyszukiwarkę, która jest wersją nadrzędną strony, i to właśnie ta strona powinna pojawiać się w wynikach wyszukiwania, a nie inne duplikaty strony. Kiedy ludzie szukają treści, do których mogą prowadzić linki, pojawi się kanonizowana strona, a oni wybiorą tę, która buduje sprawiedliwość linków. Co więcej, metryki dla fragmentu treści są konsolidowane na jednej stronie, co sprawia, że raporty metryk są bardziej wiarygodne.
Jak prawidłowo używać znaczników kanonicznych
Załóżmy, że w Twojej witrynie (lub w dwóch różnych witrynach) znajdują się zduplikowane treści, ale główna wersja, na którą chcesz kierować wyszukiwarki, to http://example.com/blogpost .
Tag kanoniczny dodany do kodu źródłowego posta na blogu (nagłówek kodu HTML strony) będzie wyglądał następująco:
Jeśli korzystasz z WordPressa, nie musisz manipulować kodem HTML, jak w przypadku innych platform CMS. Zamiast tego możesz użyć wtyczki i ustawić kanoniczny adres URL dla każdej strony. Za chwilę zajmiemy się tym bardziej.
Kanoniczne adresy URL i kopiowane treści
Skopiowana treść może stanowić problem. Dzięki kanonicznym adresom URL każdy, kto zamierza skopiować treść, wie, którego tagu użyć w nagłówku strony. Kopiarka ma jednak obowiązek poinformować wyszukiwarki, że skopiowały treść, umieszczając rel=”canonical” w nagłówku swojej witryny i wskazując z powrotem na Twoją treść.
Innym razem możesz chcieć zostać kopiarką. Zdarza się to na przykład w przypadku komunikatów prasowych. Możesz najpierw opublikować informację prasową w witrynie swojej firmy, ale oryginalne źródło treści przypisz do sieci dystrybucyjnej. To uczyniłoby cię syndykatorem, a nie oryginalnym wydawcą – przynajmniej według wyszukiwarek.
Należy jednak pamiętać, że uwzględnienie kanonicznego adresu URL w kopiowanej treści nie zawsze jest konieczne. Albo czasami jest ignorowane. Wyszukiwarki wykonują świetną robotę, znajdując prawdziwe oryginalne źródło treści. Jeśli więc zamierzasz użyć kanonicznego adresu URL do wskazywania nieoryginalnego, jak w powyższym przykładzie komunikatu prasowego, po prostu wiedz, że wyszukiwarka może go zignorować. Użyj tej taktyki według własnego uznania. To coś w rodzaju obrzydliwej szarej strefy dla SEO, jeśli nie pełnej taktyki czarnego kapelusza.
Wybór struktury adresu URL
Nawet jeśli uważasz, że nie masz zduplikowanych treści w dowolnym miejscu online, struktura Twoich adresów URL może przypadkowo tworzyć zduplikowane treści. Na przykład, nawet jeśli poniższe adresy URL wyświetlają tę samą treść i uznasz je za tę samą stronę, wyszukiwarki widzą je jako oddzielne:
- http://www.examplesite.com – zawiera „www”
- http://examplesite.com – nie zawiera „www”
- https://examplesite.com – zawiera „https” zamiast „http”
- http://www.examplesite.com/ – na końcu jest ukośnik
Istnieją również odmiany HTTPS i końcowych ukośników oraz www. Wszystkie są postrzegane jako osobne strony według wyszukiwarek.
Oznacza to, że musisz podjąć ostateczną decyzję dotyczącą struktury swoich adresów URL. Następnie używaj tej struktury wszędzie — w swojej witrynie i wszędzie tam, gdzie się do niej odsyłasz. Jeśli musisz zaktualizować swoje adresy URL, przejdź do struktury, której używasz najczęściej, aby ten proces był mniej żmudny. Jeśli jednak pobierasz poufne informacje ze swojej witryny, takie jak informacje o karcie kredytowej, będziesz chciał użyć protokołu HTTPS.
Zduplikowana treść może również zostać przypadkowo utworzona przez kategorie i tagi WordPress. Na przykład te dwa adresy URL mogą prowadzić do tej samej strony, ale wyszukiwarka zobaczy je jako dwie oddzielne strony ze zduplikowaną treścią:
- http://examplesite.com/store/cukierki/czekoladowe-trufle
- http://examplesite.com/store/foods/czekoladowe-trufle
Możesz chcieć, aby użytkownicy znajdowali czekoladowe trufle, niezależnie od tego, czy szukają w Twojej witrynie kategorii „Cukierki”, czy „Żywność”. Ale wyszukiwarki nadal muszą wiedzieć, który z nich należy umieścić w wynikach wyszukiwania. Dlatego większość wtyczek SEO, takich jak Yoast i Rank Math, oferuje opcję odindeksowania stron archiwów. W ten sposób te duplikaty nie będą widoczne dla Googlebota i jego odpowiedników.
Kiedy nie używać kanonicznych adresów URL
Jeśli chodzi o przekierowania 301, możesz nie chcieć używać tagu kanonicznego. Pomyśl o różnicy w ten sposób: przekierowanie oznacza, że jest tylko jedno miejsce, w którym pojawia się treść, i zmuszasz wszystkich odwiedzających do przejścia na tę jedną stronę. Z drugiej strony, dzięki kanonicznemu adresowi URL, wiele stron zawierających tę samą treść może istnieć i być przeglądanych, z jednym oryginalnym źródłem przeznaczonym dla wyszukiwarek.

Ponadto element adresu URL rel="canonical" nie jest rozwiązaniem wszystkich problemów z duplikatami treści. SEO to złożony temat, a czasami bardziej odpowiednim rozwiązaniem jest użycie pliku robots zamiast indeksowania strony. Zaleca się, aby nie indeksować stron, które nie są pożądanymi punktami wejścia do witryny, a także stron, które nie są zbyt przydatne dla większości odwiedzających. Na przykład, czy naprawdę chcesz, aby strona z warunkami umowy pojawiała się w wynikach wyszukiwania? Prawdopodobnie nie. Ale Twoje posty na blogu, opisy produktów i strony sprzedażowe? Zdecydowanie.
Dobrym pomysłem jest również zapoznanie się z artykułem Google z pięcioma typowymi błędami podczas korzystania z tagu kanonicznego. Nie ma nic lepszego niż to, co mówi bezpośrednio Google.
Jak kanoniczne adresy URL wpływają na SEO?
Chociaż zdecydowanie zalecamy rozwiązywanie problemów ze zduplikowaną treścią za pomocą kanonicznych adresów URL, należy pamiętać, że z technicznego punktu widzenia Google nie karze witryn za publikowanie zduplikowanych treści. Może to jednak zaszkodzić rankingowi w wyszukiwarkach — co i tak przypomina karę. Kiedy wyszukiwarki mają trudności z ustaleniem, która wersja treści jest nadrzędna, żadna wersja nie jest wysoko oceniana.
Możliwe jest również, że wyszukiwarka wybierze niewłaściwą wersję i link do niewiarygodnej witryny, co oznacza, że może w ogóle nie zostać kliknięta i odczytana, jeśli użytkownikom nie spodoba się wygląd adresu URL. Co więcej, gdy w Twojej witrynie znajdują się zduplikowane treści, budżet indeksowania zostaje pochłonięty. Wyszukiwarki indeksują i ponownie indeksują witryny w celu znalezienia nowej treści, a jeśli w witrynie znajdują się zduplikowane treści, przemierzanie ich wszystkich trwa dłużej. Oznacza to, że wyszukiwarka zajmie więcej czasu na zindeksowanie nowych stron i uszeregowanie ich w wynikach wyszukiwania.
Możesz bardziej zagłębić się w ten temat, czytając nasz Kompletny przewodnik po duplikowaniu treści i SEO. Google ma również pomocną stronę o konsolidacji zduplikowanych adresów URL.
Jak ustawić kanoniczny adres URL
W tej sekcji omówimy, jak ustawić kanoniczny adres URL w WordPressie i na stronie innej niż WordPress.
Ustaw kanoniczny adres URL za pomocą WordPress
Chociaż możesz ustawić kanoniczne adresy URL bez wtyczki WordPress, uważamy, że najlepszą, najbardziej niezawodną i elastyczną opcją jest użycie wtyczki. W tym przewodniku używamy Yoast SEO.
Po zainstalowaniu i aktywacji Yoast SEO otwórz stronę lub post WordPress. Przewiń w dół posta, aż dojdziesz do pola Yoast SEO. Po wybraniu zakładki SEO (będzie ona domyślnie), przewiń w dół, a następnie kliknij Zaawansowane . U dołu wyświetlonego menu zobaczysz boks oznaczony jako Kanoniczny URL .
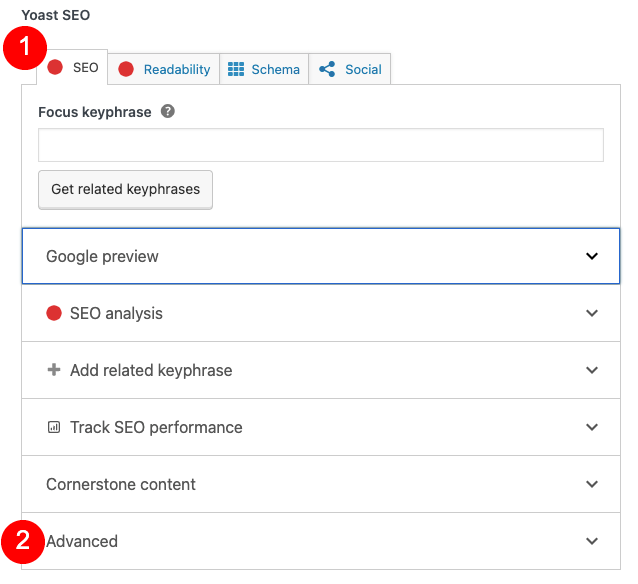
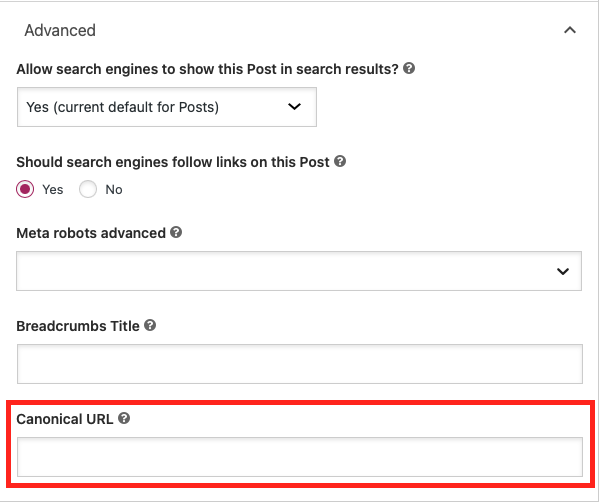
Wprowadź w tym polu pełny adres URL, a następnie zapisz zmiany w poście lub na stronie.
All in One SEO i Rank Math SEO to dwie inne wtyczki, które warto rozważyć.
Ustaw kanoniczny adres URL poza WordPress
Jeśli nie korzystasz z WordPressa, nadal możesz ustawić kanoniczne adresy URL. Najpierw musisz uzyskać dostęp do kodu HTML strony. Każdy twórca stron internetowych będzie miał swój własny proces, ale powinien być dość łatwy do znalezienia. Na przykład, oto jak dodać kod do witryny Wix. Proces jest podobny dla większości konstruktorów innych niż WP i platform CMS; musisz tylko znaleźć miejsce, w którym możesz edytować stronę/publikować HTML.
Następnie dodasz adres URL z tagiem rel="canonical" dołączonym do sekcji head. Korzystając z poniższego przykładu, zastąp http://example.com/blogpost swoim adresem URL:
Sekcja nagłówka HTML to pierwsza część kodu. Otwiera się i zamyka. Oto przykład:
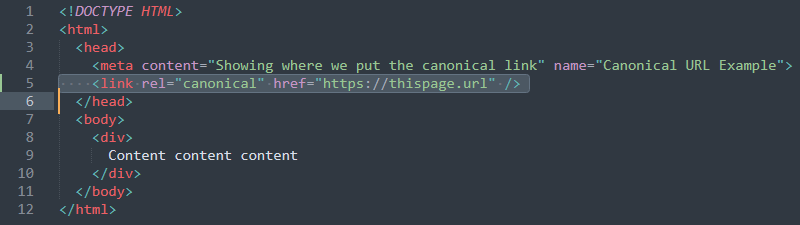
Aby dodać kod do sekcji head, musisz umieścić go gdzieś pomiędzy tagami open i close. Najlepiej dodać link nad zamykającym tagiem, aby wszystko było uporządkowane.
Jak znaleźć kanoniczny adres URL
Jeśli chcesz sprawdzić, czy strona internetowa ma wyznaczony kanoniczny adres URL, jest to bardzo proste. Otwórz stronę, a następnie kliknij prawym przyciskiem myszy, co spowoduje wyświetlenie menu. Wybierz opcję Pokaż źródło strony (lub inną opcję zbliżoną do tego, np. Wyświetl źródło strony ). To otworzy stronę źródłową z kodem HTML. U góry powinieneś zobaczyć sekcję głowy. Sprawdź w tej sekcji tag rel="canonical".
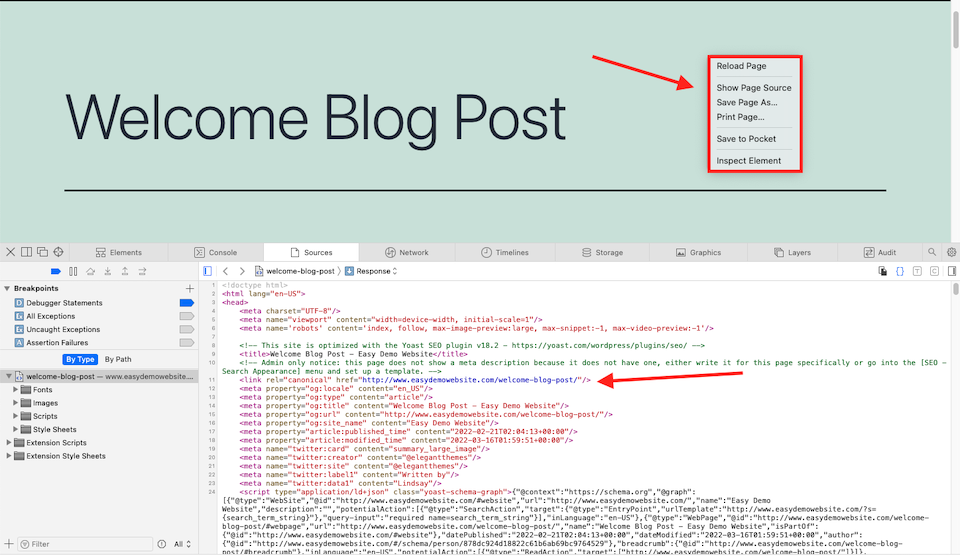
Jak usunąć kanoniczny adres URL
Usunięcie kanonicznego adresu URL jest również dość łatwe. Po prostu wykonujesz te same kroki, które wykonałeś, aby dodać adres URL, ale tym razem go usuń. Jeśli użyłeś wtyczki takiej jak Yoast, możesz przejść do strony i usunąć kanoniczny adres URL z powiązanego pola. Jeśli dodałeś go bezpośrednio do kodu HTML strony, możesz go po prostu usunąć, a następnie zaktualizować stronę. Dlatego też dobrze jest zawsze dodawać kanoniczne adresy URL w tym samym miejscu, na przykład bezpośrednio nad zamykającym tagiem head.
Ostatnie przemyślenia na temat kanonicznych adresów URL
Im więcej stron masz w swojej witrynie, tym bardziej pracochłonne będzie wdrożenie strategii kanonicznych adresów URL. Dlatego najlepiej zajmij się tym jak najwcześniej i pilnuj, gdzie Twoje treści są ponownie publikowane online. Dzięki przydatnym wtyczkom WordPress, takim jak Yoast SEO, ustawianie kanonicznych adresów URL jest łatwiejsze niż konieczność dostępu do kodu HTML każdej strony i ręcznej edycji kodu.
Jakie są Twoje sprawdzone metody korzystania z kanonicznych adresów URL? Daj nam znać w komentarzach!
Artykuł wyróżniony obrazem autorstwa Thepanyo / shutterstock.com