
Lista de rastreadores: Web Crawler Bots e como aproveitá-los para o sucesso
Publicados: 2022-12-03Para a maioria dos profissionais de marketing, atualizações constantes são necessárias para manter seu site atualizado e melhorar suas classificações de SEO.
No entanto, alguns sites têm centenas ou até milhares de páginas, tornando-se um desafio para as equipes que enviam manualmente as atualizações para os mecanismos de pesquisa. Se o conteúdo está sendo atualizado com tanta frequência, como as equipes podem garantir que essas melhorias estão impactando suas classificações de SEO?
É aí que entram os robôs rastreadores. Um bot rastreador da web irá raspar seu sitemap para novas atualizações e indexar o conteúdo nos motores de busca.
Nesta postagem, descreveremos uma lista abrangente de rastreadores que abrange todos os bots de rastreadores da Web que você precisa conhecer. Antes de nos aprofundarmos, vamos definir os bots do rastreador da Web e mostrar como eles funcionam.
O que é um rastreador da Web?
Um rastreador da Web é um programa de computador que verifica automaticamente e lê sistematicamente páginas da Web para indexá-las para os mecanismos de pesquisa. Os rastreadores da Web também são conhecidos como spiders ou bots.
Para que os mecanismos de pesquisa apresentem páginas da Web relevantes e atualizadas aos usuários que iniciam uma pesquisa, deve ocorrer um rastreamento de um bot rastreador da Web. Às vezes, esse processo pode ocorrer automaticamente (dependendo das configurações do rastreador e do seu site) ou pode ser iniciado diretamente.
Muitos fatores afetam a classificação de SEO de suas páginas, incluindo relevância, backlinks, hospedagem na web e muito mais. No entanto, nada disso importa se suas páginas não estiverem sendo rastreadas e indexadas pelos mecanismos de pesquisa. É por isso que é tão vital garantir que seu site esteja permitindo que os rastreamentos corretos ocorram e removendo quaisquer barreiras em seu caminho.
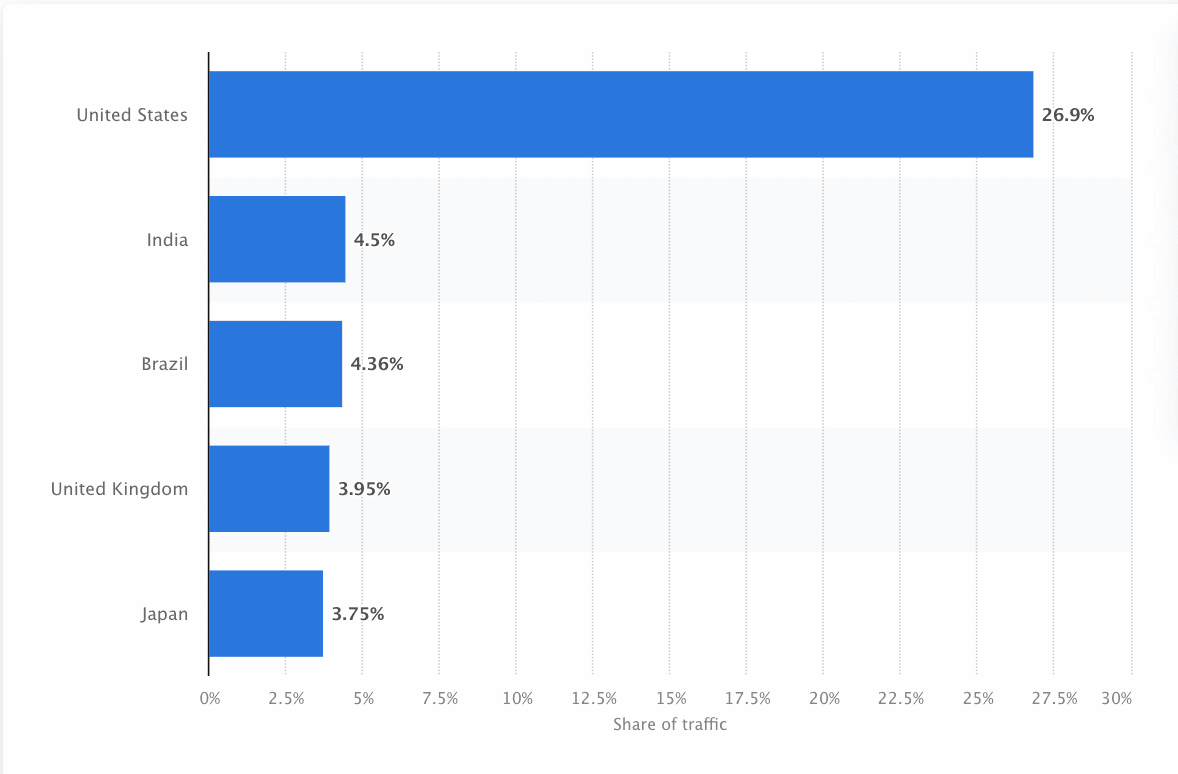
Os bots devem escanear e raspar continuamente a web para garantir que as informações mais precisas sejam apresentadas. O Google é o site mais visitado nos Estados Unidos e aproximadamente 26,9% das pesquisas vêm de usuários americanos:
No entanto, não há um rastreador da Web que rastreie todos os mecanismos de pesquisa. Cada mecanismo de pesquisa tem pontos fortes exclusivos, portanto, desenvolvedores e profissionais de marketing às vezes compilam uma “lista de rastreadores”. Essa lista de rastreadores os ajuda a identificar diferentes rastreadores no registro do site para aceitar ou bloquear.
Os profissionais de marketing precisam montar uma lista de rastreadores cheia dos diferentes rastreadores da Web e entender como eles avaliam seu site (ao contrário dos raspadores de conteúdo que roubam o conteúdo) para garantir que otimizem suas páginas de destino corretamente para os mecanismos de pesquisa.
Como funciona um rastreador da Web?
Um rastreador da web verificará automaticamente sua página da web depois que ela for publicada e indexará seus dados.
Os rastreadores da Web procuram palavras-chave específicas associadas à página da Web e indexam essas informações para mecanismos de pesquisa relevantes, como Google, Bing e outros.
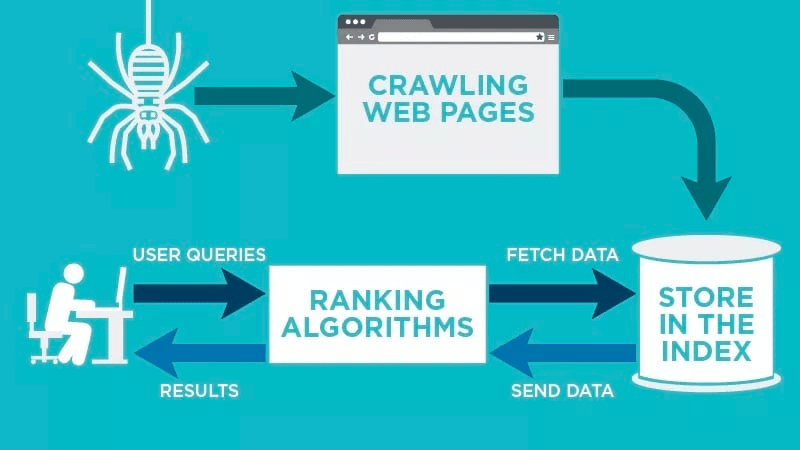
Algoritmos para os mecanismos de pesquisa buscarão esses dados quando um usuário enviar uma consulta para a palavra-chave relevante que está vinculada a ela.
Os rastreamentos começam com URLs conhecidos. Estas são páginas da web estabelecidas com vários sinais que direcionam os rastreadores da web para essas páginas. Esses sinais podem ser:
- Backlinks: o número de vezes que um site se vincula a ele
- Visitantes: quanto tráfego está indo para essa página
- Autoridade de domínio: a qualidade geral do domínio
Em seguida, eles armazenam os dados no índice do mecanismo de pesquisa. À medida que o usuário inicia uma consulta de pesquisa, o algoritmo buscará os dados do índice e aparecerá na página de resultados do mecanismo de pesquisa. Esse processo pode ocorrer em alguns milissegundos, e é por isso que os resultados geralmente aparecem rapidamente.
Como webmaster, você pode controlar quais bots rastreiam seu site. É por isso que é importante ter uma lista de rastreadores. É o protocolo robots.txt que reside nos servidores de cada site que direciona os rastreadores para o novo conteúdo que precisa ser indexado.
Dependendo do que você insere em seu protocolo robots.txt em cada página da Web, você pode instruir um rastreador a verificar ou evitar a indexação dessa página no futuro.
Ao entender o que um rastreador da Web procura em sua verificação, você pode entender como posicionar melhor seu conteúdo para os mecanismos de pesquisa.
Compilando sua lista de rastreadores: quais são os diferentes tipos de rastreadores da Web?
Conforme você começa a pensar em compilar sua lista de rastreadores, existem três tipos principais de rastreadores a serem procurados. Esses incluem:
- Rastreadores internos: são rastreadores projetados pela equipe de desenvolvimento de uma empresa para escanear seu site. Normalmente, eles são usados para auditoria e otimização do site.
- Rastreadores comerciais: são rastreadores personalizados, como o Screaming Frog, que as empresas podem usar para rastrear e avaliar com eficiência seu conteúdo.
- Rastreadores de código aberto : são rastreadores de uso gratuito criados por uma variedade de desenvolvedores e hackers em todo o mundo.
É importante entender os diferentes tipos de rastreadores existentes para saber qual tipo você precisa utilizar para atingir seus próprios objetivos de negócios.
Os 11 rastreadores da Web mais comuns para adicionar à sua lista de rastreadores
Não existe um rastreador que faça todo o trabalho para todos os mecanismos de pesquisa.
Em vez disso, há uma variedade de rastreadores da Web que avaliam suas páginas da Web e verificam o conteúdo de todos os mecanismos de pesquisa disponíveis para usuários em todo o mundo.
Vejamos alguns dos rastreadores da web mais comuns atualmente.
1. Googlebot
O Googlebot é o rastreador da Web genérico do Google, responsável por rastrear sites que aparecerão no mecanismo de pesquisa do Google.

Embora existam tecnicamente duas versões do Googlebot - Googlebot Desktop e Googlebot Smartphone (Mobile) - a maioria dos especialistas considera o Googlebot um único rastreador.
Isso ocorre porque ambos seguem o mesmo token de produto exclusivo (conhecido como token de agente do usuário) escrito no robots.txt de cada site. O agente de usuário do Googlebot é simplesmente "Googlebot".
O Googlebot entra em ação e normalmente acessa seu site a cada poucos segundos (a menos que você o tenha bloqueado no robots.txt do seu site). Um backup das páginas digitalizadas é salvo em um banco de dados unificado chamado Google Cache. Isso permite que você veja versões antigas do seu site.
Além disso, o Google Search Console também é outra ferramenta que os webmasters usam para entender como o Googlebot está rastreando seu site e para otimizar suas páginas para pesquisa.
2. Bingbot
O Bingbot foi criado em 2010 pela Microsoft para digitalizar e indexar URLs para garantir que o Bing ofereça resultados relevantes e atualizados do mecanismo de pesquisa para os usuários da plataforma.
Assim como o Googlebot, os desenvolvedores ou profissionais de marketing podem definir em seu robots.txt em seu site se aprovam ou negam o identificador de agente “bingbot” para verificar seu site.
Além disso, eles têm a capacidade de distinguir entre rastreadores de indexação mobile-first e rastreadores de desktop desde que o Bingbot mudou recentemente para um novo tipo de agente. Isso, juntamente com o Bing Webmaster Tools, fornece aos webmasters maior flexibilidade para mostrar como seu site é descoberto e exibido nos resultados de pesquisa.
3. Bot Yandex
Yandex Bot é um rastreador especificamente para o mecanismo de busca russo, Yandex. Este é um dos maiores e mais populares mecanismos de pesquisa da Rússia.

Os webmasters podem tornar as páginas do site acessíveis ao Yandex Bot por meio do arquivo robots.txt .
Além disso, eles também podem adicionar uma tag Yandex.Metrica a páginas específicas, reindexar páginas no Yandex Webmaster ou emitir um protocolo IndexNow, um relatório exclusivo que aponta páginas novas, modificadas ou desativadas.
4. Bot da Apple
A Apple encomendou o Apple Bot para rastrear e indexar páginas da Web para Siri e Spotlight Suggestions da Apple.
O Apple Bot considera vários fatores ao decidir qual conteúdo elevar na Siri e nas Sugestões do Spotlight. Esses fatores incluem o envolvimento do usuário, a relevância dos termos de pesquisa, o número/qualidade dos links, os sinais baseados em localização e até mesmo o design da página da web.
5. DuckDuck Bot
O DuckDuckBot é o rastreador da web para DuckDuckGo, que oferece “Proteção de privacidade perfeita em seu navegador da web”.
Os webmasters podem usar a API DuckDuckBot para ver se o DuckDuck Bot rastreou seu site. À medida que rastreia, ele atualiza o banco de dados da API do DuckDuckBot com endereços IP recentes e agentes de usuário.
Isso ajuda os webmasters a identificar quaisquer impostores ou bots maliciosos tentando se associar ao DuckDuck Bot.
6. Aranha Baidu
O Baidu é o principal mecanismo de busca chinês, e o Baidu Spider é o único rastreador do site.

O Google é proibido na China, por isso é importante habilitar o Baidu Spider para rastrear seu site se você quiser alcançar o mercado chinês.
Para identificar o Baidu Spider rastreando seu site, procure os seguintes agentes de usuário: baiduspider, baiduspider-image, baiduspider-video e muito mais.
Se você não estiver fazendo negócios na China, pode fazer sentido bloquear o Baidu Spider em seu script robots.txt. Isso impedirá que o Baidu Spider rastreie seu site, removendo assim qualquer chance de suas páginas aparecerem nas páginas de resultados do mecanismo de pesquisa (SERPs) do Baidu.
7. Aranha Sogou
Sogou é um mecanismo de busca chinês que é supostamente o primeiro mecanismo de busca com 10 bilhões de páginas chinesas indexadas.


Se você está fazendo negócios no mercado chinês, este é outro rastreador de mecanismo de pesquisa popular que você precisa conhecer. O Sogou Spider segue o texto de exclusão do robô e os parâmetros de atraso de rastreamento.
Assim como o Baidu Spider, se você não quiser fazer negócios no mercado chinês, desative esse spider para evitar lentidão no carregamento do site.
8. Hit externo do Facebook
O Facebook External Hit, também conhecido como Facebook Crawler, rastreia o HTML de um aplicativo ou site compartilhado no Facebook.

Isso permite que a plataforma social gere uma visualização compartilhável de cada link postado na plataforma. O título, a descrição e a imagem em miniatura aparecem graças ao rastreador.
Se o rastreamento não for executado em segundos, o Facebook não mostrará o conteúdo no snippet personalizado gerado antes do compartilhamento.
9. Exabot
Exalead é uma empresa de software criada em 2000 e sediada em Paris, França. A empresa fornece plataformas de pesquisa para consumidores e clientes corporativos.
O Exabot é o rastreador de seu principal mecanismo de pesquisa criado em seu produto CloudView.
Como a maioria dos mecanismos de pesquisa, o Exalead considera tanto o backlink quanto o conteúdo das páginas da web ao classificar. Exabot é o agente do usuário do robô Exalead. O robô cria um “índice principal” que compila os resultados que os usuários do mecanismo de pesquisa verão.
10. Swiftbot
Swiftype é um mecanismo de pesquisa personalizado para o seu site. Ele combina “a melhor tecnologia de pesquisa, algoritmos, estrutura de ingestão de conteúdo, clientes e ferramentas de análise”.
Se você tem um site complexo com muitas páginas, o Swiftype oferece uma interface útil para catalogar e indexar todas as suas páginas para você.
Swiftbot é o rastreador da web do Swiftype. No entanto, ao contrário de outros bots, o Swiftbot rastreia apenas sites solicitados por seus clientes.
11. Slurp Bot
Slurp Bot é o robô de busca do Yahoo que rastreia e indexa páginas para o Yahoo.
Esse rastreamento é essencial tanto para o Yahoo.com quanto para os sites de seus parceiros, incluindo Yahoo News, Yahoo Finance e Yahoo Sports. Sem ele, as listas de sites relevantes não apareceriam.
O conteúdo indexado contribui para uma experiência web mais personalizada para os usuários com resultados mais relevantes.
Os 8 rastreadores comerciais que os profissionais de SEO precisam saber
Agora que você tem 11 dos bots mais populares em sua lista de rastreadores, vamos ver alguns dos rastreadores comerciais comuns e ferramentas de SEO para profissionais.
1. Bot Ahrefs
O Ahrefs Bot é um rastreador da web que compila e indexa o banco de dados de 12 trilhões de links que o popular software de SEO Ahrefs oferece.
O Ahrefs Bot visita 6 bilhões de sites todos os dias e é considerado “o segundo rastreador mais ativo” atrás apenas do Googlebot.
Assim como outros bots, o Ahrefs Bot segue as funções do robots.txt , bem como permite/não permite regras no código de cada site.
2. Semrush Bot
O Semrush Bot permite que o Semrush, um software de SEO líder, colete e indexe dados do site para uso de seus clientes em sua plataforma.
Os dados são usados no mecanismo de pesquisa de backlinks públicos da Semrush, na ferramenta de auditoria do site, na ferramenta de auditoria de backlinks, na ferramenta de criação de links e no assistente de redação.
Ele rastreia seu site compilando uma lista de URLs de páginas da Web, visitando-os e salvando determinados hiperlinks para futuras visitas.
3. Moz's Campaign Crawler Rogerbot
Rogerbot é o rastreador do principal site de SEO, Moz. Este rastreador está coletando conteúdo especificamente para auditorias de sites da Moz Pro Campaign.

O Rogerbot segue todas as regras estabelecidas nos arquivos robots.txt , então você pode decidir se deseja bloquear/permitir que o Rogerbot escaneie seu site.
Os webmasters não poderão pesquisar um endereço IP estático para ver quais páginas o Rogerbot rastreou devido à sua abordagem multifacetada.
4. Sapo gritando
O Screaming Frog é um rastreador que os profissionais de SEO usam para auditar seu próprio site e identificar áreas de melhoria que afetarão suas classificações nos mecanismos de pesquisa.

Depois que um rastreamento é iniciado, você pode revisar dados em tempo real e identificar links quebrados ou melhorias necessárias para os títulos de sua página, metadados, robôs, conteúdo duplicado e muito mais.
Para configurar os parâmetros de rastreamento, você deve adquirir uma licença do Screaming Frog.
5. Lumar (anteriormente Deep Crawl)
Lumar é um “centro de comando centralizado para manter a integridade técnica do seu site”. Com esta plataforma, você pode iniciar um rastreamento do seu site para ajudá-lo a planejar a arquitetura do seu site.
A Lumar se orgulha de ser o “rastreador de sites mais rápido do mercado” e se orgulha de poder rastrear até 450 URLs por segundo.
6. Majestoso
O Majestic se concentra principalmente no rastreamento e identificação de backlinks em URLs.
A empresa se orgulha de ter “uma das fontes mais completas de dados de backlink da Internet”, destacando seu índice histórico que passou de 5 para 15 anos de links em 2021.
O rastreador do site disponibiliza todos esses dados para os clientes da empresa.
7. SEO cognitivo
CognitiveSEO é outro importante software de SEO que muitos profissionais usam.
O rastreador cognitivaSEO permite que os usuários realizem auditorias abrangentes do site que informarão a arquitetura do site e a estratégia abrangente de SEO.
O bot rastreará todas as páginas e fornecerá “um conjunto de dados totalmente personalizado” exclusivo para o usuário final. Esse conjunto de dados também terá recomendações para o usuário sobre como ele pode melhorar seu site para outros rastreadores, tanto para impactar as classificações quanto para bloquear rastreadores desnecessários.
8. Oncrawl
O Oncrawl é um “rastreador de SEO e analisador de log líder do setor” para clientes de nível empresarial.
Os usuários podem configurar “perfis de rastreamento” para criar parâmetros específicos para o rastreamento. Você pode salvar essas configurações (incluindo o URL inicial, limites de rastreamento, velocidade máxima de rastreamento e mais) para executar o rastreamento facilmente novamente sob os mesmos parâmetros estabelecidos.
Preciso proteger meu site de rastreadores da Web maliciosos?
Nem todos os rastreadores são bons. Alguns podem afetar negativamente a velocidade da sua página, enquanto outros podem tentar invadir seu site ou ter intenções maliciosas.
É por isso que é importante entender como impedir que rastreadores entrem em seu site.
Ao estabelecer uma lista de rastreadores, você saberá quais rastreadores são os bons a serem observados. Então, você pode eliminar os suspeitos e adicioná-los à sua lista de bloqueio.
Como bloquear rastreadores da Web maliciosos
Com sua lista de rastreadores em mãos, você poderá identificar quais bots deseja aprovar e quais precisa bloquear.
A primeira etapa é percorrer sua lista de rastreadores e definir o agente do usuário e a string completa do agente associada a cada rastreador, bem como seu endereço IP específico. Esses são os principais fatores de identificação associados a cada bot.
Com o agente do usuário e o endereço IP, você pode combiná-los nos registros do site por meio de uma pesquisa de DNS ou correspondência de IP. Se eles não corresponderem exatamente, você pode ter um bot mal-intencionado tentando se passar por um bot real.
Em seguida, você pode bloquear o impostor ajustando as permissões usando a tag do site robots.txt .
Resumo
Os rastreadores da Web são úteis para os mecanismos de pesquisa e importantes para os profissionais de marketing entenderem.
Garantir que seu site seja rastreado corretamente pelos rastreadores certos é importante para o sucesso de sua empresa. Ao manter uma lista de rastreadores, você pode saber quais devem ser observados quando aparecerem no log do site.
Ao seguir as recomendações dos rastreadores comerciais e melhorar o conteúdo e a velocidade do seu site, você facilitará o acesso dos rastreadores ao seu site e indexará as informações corretas para os mecanismos de pesquisa e os consumidores que as procuram.