
Lista de crawler: roboți cu crawler web și cum să le folosiți pentru succes
Publicat: 2022-12-03Pentru majoritatea marketerilor, sunt necesare actualizări constante pentru a-și menține site-ul proaspăt și pentru a-și îmbunătăți clasamentul SEO.
Cu toate acestea, unele site-uri au sute sau chiar mii de pagini, ceea ce o face o provocare pentru echipele care introduc manual actualizările către motoarele de căutare. Dacă conținutul este actualizat atât de des, cum se pot asigura echipele că aceste îmbunătățiri le afectează clasamentele SEO?
Acolo intră în joc roboții cu crawler. Un robot cu crawler web vă va răzui harta site-ului pentru noi actualizări și va indexa conținutul în motoarele de căutare.
În această postare, vom schița o listă cuprinzătoare de crawler care acoperă toți roboții crawler web pe care trebuie să-i cunoașteți. Înainte să ne aprofundăm, să definim roboții crawler web și să arătăm cum funcționează aceștia.
Ce este un web crawler?
Un web crawler este un program de calculator care scanează automat și citește sistematic paginile web pentru a indexa paginile pentru motoarele de căutare. Crawlerele web sunt cunoscute și sub numele de păianjeni sau roboți.
Pentru ca motoarele de căutare să prezinte pagini web relevante și actualizate utilizatorilor care inițiază o căutare, trebuie să aibă loc o accesare cu crawlere de la un robot de crawler web. Acest proces se poate întâmpla uneori automat (în funcție de setările crawler-ului și ale site-ului dvs.) sau poate fi inițiat direct.
Mulți factori influențează clasarea SEO a paginilor tale, inclusiv relevanța, backlink-urile, găzduirea web și multe altele. Cu toate acestea, niciuna dintre acestea nu contează dacă paginile dvs. nu sunt accesate cu crawlere și indexate de motoarele de căutare. De aceea, este atât de vital să vă asigurați că site-ul dvs. permite accesarea cu crawlere corectă și elimină orice bariere în calea lor.
Boții trebuie să scaneze și să răzuiască continuu web-ul pentru a se asigura că sunt prezentate informațiile cele mai exacte. Google este cel mai vizitat site web din Statele Unite, iar aproximativ 26,9% din căutări provin de la utilizatori americani:
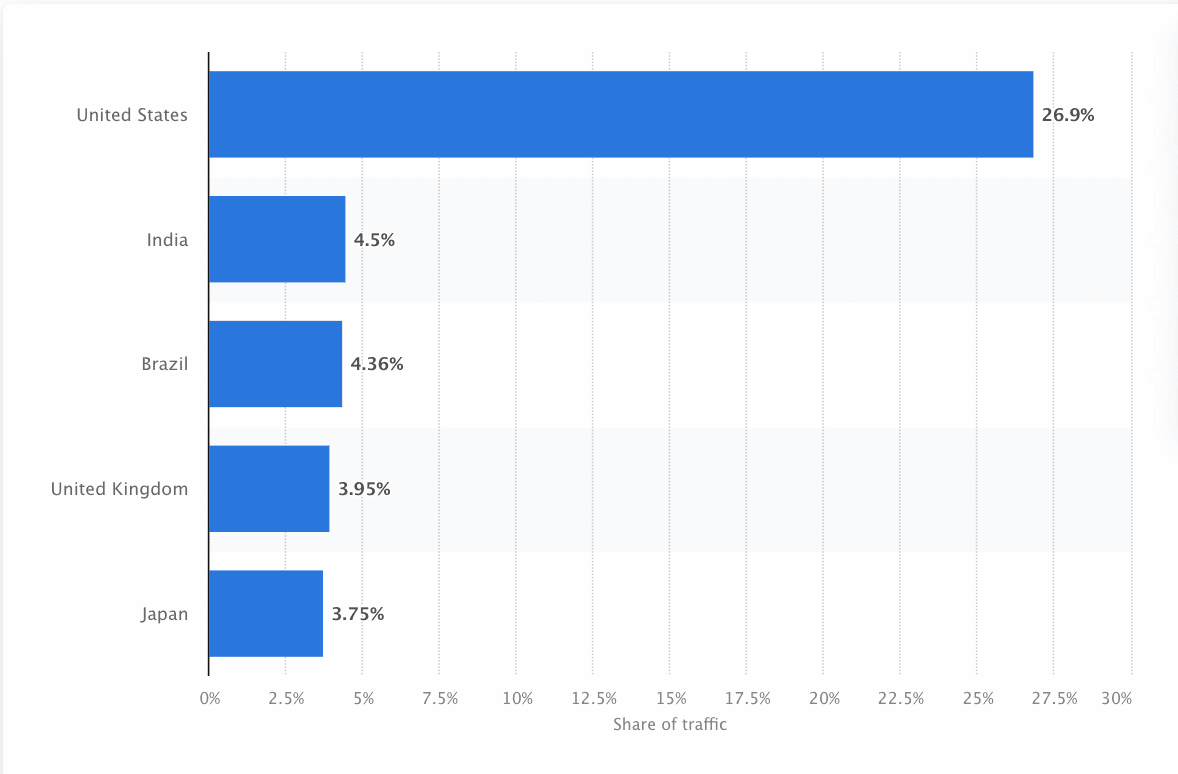
Cu toate acestea, nu există un crawler web care să se acceseze cu crawlere pentru fiecare motor de căutare. Fiecare motor de căutare are puncte forte unice, astfel încât dezvoltatorii și marketerii alcătuiesc uneori o „listă de crawler”. Această listă de crawler-uri îi ajută să identifice diferite crawler-uri în jurnalul site-ului pe care să le accepte sau să le blocheze.
Specialiștii în marketing trebuie să întocmească o listă de crawler-uri plină cu diferite crawler-uri web și să înțeleagă cum își evaluează site-ul (spre deosebire de scraper-urile de conținut care fură conținutul) pentru a se asigura că își optimizează paginile de destinație corect pentru motoarele de căutare.
Cum funcționează un crawler web?
Un crawler web va scana automat pagina dvs. web după ce este publicată și va indexa datele.
Crawlerele web caută cuvinte cheie specifice asociate cu pagina web și indexează aceste informații pentru motoarele de căutare relevante precum Google, Bing și altele.
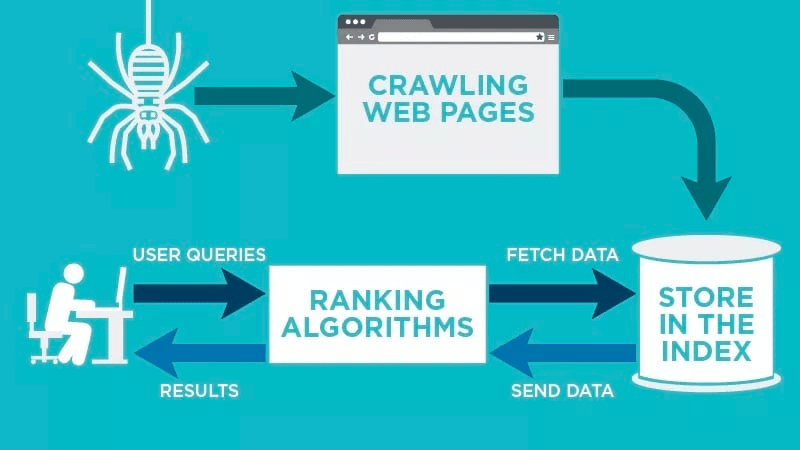
Algoritmii pentru motoarele de căutare vor prelua acele date atunci când un utilizator trimite o întrebare pentru cuvântul cheie relevant care este legat de acesta.
Accesările cu crawlere încep cu adrese URL cunoscute. Acestea sunt pagini web stabilite cu diverse semnale care direcționează crawlerele web către acele pagini. Aceste semnale pot fi:
- Backlink: de câte ori un site face link-uri către acesta
- Vizitatori: Cât trafic se îndreaptă către pagina respectivă
- Autoritate de domeniu: calitatea generală a domeniului
Apoi, ei stochează datele în indexul motorului de căutare. Pe măsură ce utilizatorul inițiază o interogare de căutare, algoritmul va prelua datele din index și va apărea pe pagina cu rezultatele motorului de căutare. Acest proces poate avea loc în câteva milisecunde, motiv pentru care rezultatele apar adesea rapid.
În calitate de webmaster, puteți controla ce roboți accesează cu crawlere site-ul dvs. De aceea este important să aveți o listă cu crawler. Este protocolul robots.txt care se află pe serverele fiecărui site și care direcționează crawlerele către conținut nou care trebuie indexat.
În funcție de ceea ce introduceți în protocolul robots.txt de pe fiecare pagină web, puteți spune unui crawler să scaneze sau să evite indexarea paginii respective în viitor.
Înțelegând ce caută un crawler web în scanarea sa, puteți înțelege cum să vă poziționați mai bine conținutul pentru motoarele de căutare.
Compilarea listei de crawler-uri: care sunt diferitele tipuri de crawler-uri web?
Pe măsură ce începeți să vă gândiți la compilarea listei de crawler-uri, există trei tipuri principale de crawler-uri de căutat. Acestea includ:
- Crawlerele interne: acestea sunt crawlerele concepute de echipa de dezvoltare a unei companii pentru a-și scana site-ul. De obicei, acestea sunt utilizate pentru auditarea și optimizarea site-ului.
- Crawler-uri comerciale: acestea sunt crawler-uri personalizate, cum ar fi Screaming Frog, pe care companiile le pot folosi pentru a accesa cu crawlere și pentru a-și evalua eficient conținutul.
- Crawler-uri cu sursă deschisă : acestea sunt crawler-uri gratuite care sunt create de o varietate de dezvoltatori și hackeri din întreaga lume.
Este important să înțelegeți diferitele tipuri de crawler-uri care există, astfel încât să știți ce tip trebuie să utilizați pentru propriile obiective de afaceri.
Cele mai comune 11 crawler-uri web pe care să le adăugați la lista dvs. de crawler-uri
Nu există un crawler care să facă toată munca pentru fiecare motor de căutare.
În schimb, există o varietate de crawler-uri web care vă evaluează paginile web și scanează conținutul pentru toate motoarele de căutare disponibile utilizatorilor din întreaga lume.
Să ne uităm la unele dintre cele mai comune crawler-uri web de astăzi.
1. Googlebot
Googlebot este crawler-ul web generic Google care este responsabil pentru accesarea cu crawlere a site-urilor care vor apărea pe motorul de căutare Google.

Deși din punct de vedere tehnic există două versiuni de Googlebot — Googlebot Desktop și Googlebot Smartphone (Mobile) — majoritatea experților consideră Googlebot un singur crawler.
Acest lucru se datorează faptului că ambele urmează același simbol unic de produs (cunoscut sub numele de simbol de agent de utilizator) scris în robots.txt al fiecărui site. Agentul utilizator Googlebot este pur și simplu „Googlebot”.
Googlebot merge la lucru și, de obicei, accesează site-ul dvs. la fiecare câteva secunde (cu excepția cazului în care l-ați blocat în robots.txt al site-ului dvs.). O copie de rezervă a paginilor scanate este salvată într-o bază de date unificată numită Google Cache. Acest lucru vă permite să priviți versiunile vechi ale site-ului dvs.
În plus, Google Search Console este, de asemenea, un alt instrument pe care webmasterii îl folosesc pentru a înțelege modul în care Googlebot își accesează cu crawlere site-ul și pentru a-și optimiza paginile pentru căutare.
2. Bingbot
Bingbot a fost creat în 2010 de Microsoft pentru a scana și indexa adresele URL pentru a se asigura că Bing oferă rezultate relevante, actualizate ale motorului de căutare pentru utilizatorii platformei.
La fel ca Googlebot, dezvoltatorii sau agenții de marketing pot defini în robots.txt de pe site-ul lor dacă aprobă sau refuză identificatorul de agent „bingbot” să-și scaneze site-ul.
În plus, au capacitatea de a distinge între crawlerele de indexare mobile-first și crawlerele desktop, deoarece Bingbot a trecut recent la un nou tip de agent. Acest lucru, împreună cu Instrumentele pentru webmasteri Bing, oferă webmasterilor o mai mare flexibilitate pentru a arăta cum site-ul lor este descoperit și prezentat în rezultatele căutării.
3. Yandex Bot
Yandex Bot este un crawler special pentru motorul de căutare rus, Yandex. Acesta este unul dintre cele mai mari și mai populare motoare de căutare din Rusia.

Webmasterii își pot face paginile site-ului accesibile pentru Yandex Bot prin fișierul robots.txt .
În plus, ar putea adăuga, de asemenea, o etichetă Yandex.Metrica la anumite pagini, reindexează paginile în Yandex Webmaster sau emite un protocol IndexNow, un raport unic care indică pagini noi, modificate sau dezactivate.
4. Apple Bot
Apple a comandat Apple Bot să acceseze cu crawlere și să indexeze paginile web pentru Siri și Spotlight Suggestions de la Apple.
Apple Bot ia în considerare mai mulți factori atunci când decide ce conținut să crească în Siri și Spotlight Suggestions. Acești factori includ implicarea utilizatorilor, relevanța termenilor de căutare, numărul/calitatea linkurilor, semnalele bazate pe locație și chiar designul paginii web.
5. DuckDuck Bot
DuckDuckBot este crawler-ul web pentru DuckDuckGo, care oferă „Protecție perfectă a confidențialității în browserul tău web”.
Webmasterii pot folosi API-ul DuckDuckBot pentru a vedea dacă DuckDuck Bot și-a accesat cu crawlere site-ul. Pe măsură ce se accesează cu crawlere, actualizează baza de date API DuckDuckBot cu adrese IP recente și agenți de utilizator.
Acest lucru îi ajută pe webmasteri să identifice orice impostori sau roboți rău intenționați care încearcă să fie asociat cu DuckDuck Bot.
6. Păianjen Baidu
Baidu este principalul motor de căutare chinezesc, iar Baidu Spider este singurul crawler al site-ului.

Google este interzis în China, așa că este important să permiteți Baidu Spider să acceseze cu crawlere site-ul dvs. dacă doriți să ajungeți pe piața chineză.
Pentru a identifica Baidu Spider care accesează cu crawlere site-ul dvs., căutați următorii agenți de utilizator: baiduspider, baiduspider-image, baiduspider-video și altele.
Dacă nu faceți afaceri în China, ar putea avea sens să blocați Baidu Spider în scriptul robots.txt. Acest lucru va împiedica Baidu Spider să acceseze cu crawlere site-ul dvs., eliminând astfel orice șansă ca paginile dvs. să apară în paginile cu rezultate ale motorului de căutare (SERP-uri) Baidu.
7. Păianjen Sogou
Sogou este un motor de căutare chinezesc care se pare că este primul motor de căutare cu 10 miliarde de pagini chineze indexate.


Dacă faci afaceri pe piața chineză, acesta este un alt crawler popular pentru motorul de căutare despre care trebuie să știi. Păianjenul Sogou urmează textul de excludere a robotului și parametrii de întârziere a accesului cu crawlere.
Ca și în cazul lui Baidu Spider, dacă nu doriți să faceți afaceri pe piața chineză, ar trebui să dezactivați acest spider pentru a preveni timpii de încărcare lenți ai site-ului.
8. Hit extern Facebook
Facebook External Hit, cunoscut și sub numele de Facebook Crawler, accesează cu crawlere codul HTML al unei aplicații sau al unui site web partajat pe Facebook.

Acest lucru permite platformei sociale să genereze o previzualizare care poate fi partajată a fiecărui link postat pe platformă. Titlul, descrierea și imaginea în miniatură apar datorită crawlerului.
Dacă accesarea cu crawlere nu este executată în câteva secunde, Facebook nu va afișa conținutul în fragmentul personalizat generat înainte de partajare.
9. Exabot
Exalead este o companie de software creată în 2000 și cu sediul în Paris, Franța. Compania oferă platforme de căutare pentru clienții consumatori și întreprinderi.
Exabot este crawler-ul motorului lor de căutare de bază construit pe produsul lor CloudView.
La fel ca majoritatea motoarelor de căutare, Exalead ia în considerare atât backlink-ul, cât și conținutul paginilor web atunci când se clasează. Exabot este agentul utilizator al robotului Exalead. Robotul creează un „index principal” care compilează rezultatele pe care le vor vedea utilizatorii motorului de căutare.
10. Swiftbot
Swiftype este un motor de căutare personalizat pentru site-ul dvs. web. Combină „cea mai bună tehnologie de căutare, algoritmi, cadru de asimilare de conținut, clienți și instrumente de analiză”.
Dacă aveți un site complex cu multe pagini, Swiftype vă oferă o interfață utilă pentru a vă cataloga și indexa toate paginile.
Swiftbot este crawler-ul web al Swiftype. Cu toate acestea, spre deosebire de alți roboți, Swiftbot accesează cu crawlere doar site-urile solicitate de clienții lor.
11. Slurp Bot
Slurp Bot este robotul de căutare Yahoo care accesează cu crawlere și indexează paginile pentru Yahoo.
Această accesare cu crawlere este esențială atât pentru Yahoo.com, cât și pentru site-urile partenere, inclusiv Yahoo News, Yahoo Finance și Yahoo Sports. Fără el, înregistrările relevante de site-uri nu ar apărea.
Conținutul indexat contribuie la o experiență web mai personalizată pentru utilizatori, cu rezultate mai relevante.
Cei 8 profesioniști SEO pentru crawlerele comerciale pe care trebuie să le cunoască
Acum că aveți 11 dintre cei mai populari roboți pe lista dvs. de crawler, să ne uităm la unele dintre crawlerele comerciale comune și instrumentele SEO pentru profesioniști.
1. Ahrefs Bot
Ahrefs Bot este un crawler web care compilează și indexează baza de date de 12 trilioane de linkuri pe care o oferă software-ul popular SEO Ahrefs.
Ahrefs Bot vizitează 6 miliarde de site-uri web în fiecare zi și este considerat „al doilea cel mai activ crawler” după numai Googlebot.
La fel ca alți roboți, Ahrefs Bot urmează funcțiile robots.txt , precum și permite/interzice reguli în codul fiecărui site.
2. Semrush Bot
Semrush Bot îi permite lui Semrush, un software SEO de top, să colecteze și să indexeze datele site-ului pentru utilizarea de către clienții săi pe platforma sa.
Datele sunt utilizate în motorul de căutare public de backlink al Semrush, instrumentul de audit al site-ului, instrumentul de audit backlink, instrumentul de creare a linkurilor și asistentul de scriere.
Acesta vă accesează cu crawlere site-ul compilând o listă de adrese URL a paginilor web, vizitându-le și salvând anumite hyperlinkuri pentru vizite viitoare.
3. Moz's Campaign Crawler Rogerbot
Rogerbot este crawler-ul principalului site SEO, Moz. Acest crawler colectează în mod special conținut pentru auditurile site-ului Moz Pro Campaign.

Rogerbot respectă toate regulile stabilite în fișierele robots.txt , așa că puteți decide dacă doriți să blocați/permiteți ca Rogerbot să vă scaneze site-ul.
Webmasterii nu vor putea căuta o adresă IP statică pentru a vedea ce pagini a accesat Rogerbot cu crawlere din cauza abordării sale cu mai multe fațete.
4. Broasca care tipa
Screaming Frog este un crawler pe care profesioniștii SEO îl folosesc pentru a-și audita propriul site și pentru a identifica zonele de îmbunătățire care le vor afecta clasamentul în motoarele de căutare.

Odată inițiată o accesare cu crawlere, puteți examina datele în timp real și puteți identifica linkurile întrerupte sau îmbunătățirile necesare pentru titlurile paginii, metadate, roboți, conținut duplicat și multe altele.
Pentru a configura parametrii de accesare cu crawlere, trebuie să achiziționați o licență Screaming Frog.
5. Lumar (fost Deep Crawl)
Lumar este un „centru de comandă centralizat pentru menținerea sănătății tehnice a site-ului dumneavoastră”. Cu această platformă, puteți iniția o accesare cu crawlere a site-ului dvs. pentru a vă ajuta să vă planificați arhitectura site-ului.
Lumar se mândrește ca fiind „cel mai rapid crawler de site-uri de pe piață” și se laudă că poate accesa cu crawlere până la 450 de adrese URL pe secundă.
6. Majestuos
Majestic se concentrează în primul rând pe urmărirea și identificarea backlink-urilor pe adrese URL.
Compania se mândrește cu „una dintre cele mai cuprinzătoare surse de date de backlink de pe internet”, subliniind indexul său istoric, care a crescut de la 5 la 15 ani de link-uri în 2021.
Crawler-ul site-ului pune toate aceste date la dispoziția clienților companiei.
7. SEO cognitiv
cognitiveSEO este un alt software SEO important pe care îl folosesc mulți profesioniști.
Crawler-ul cognitiveSEO le permite utilizatorilor să efectueze audituri complete ale site-ului care le vor informa arhitectura site-ului și strategia generală de SEO.
Botul va accesa cu crawlere toate paginile și va oferi „un set complet personalizat de date”, care este unic pentru utilizatorul final. Acest set de date va avea și recomandări pentru utilizator cu privire la modul în care își pot îmbunătăți site-ul pentru alte crawler-uri – atât pentru a afecta clasamentele, cât și pentru a bloca crawlerele care nu sunt necesare.
8. Oncrawl
Oncrawl este un „crawler SEO și analizor de jurnal lider în industrie” pentru clienții la nivel de întreprindere.
Utilizatorii pot configura „profiluri de accesare cu crawlere” pentru a crea parametri specifici pentru accesare cu crawlere. Puteți salva aceste setări (inclusiv adresa URL de pornire, limitele de accesare cu crawlere, viteza maximă de accesare cu crawlere și multe altele) pentru a rula cu ușurință din nou accesarea cu crawlere sub aceiași parametri stabiliți.
Trebuie să îmi protejez site-ul de crawlerele web rău intenționate?
Nu toate crawlerele sunt bune. Unele pot avea un impact negativ asupra vitezei paginii dvs., în timp ce altele pot încerca să vă spargă site-ul sau să aibă intenții rău intenționate.
De aceea, este important să înțelegeți cum să blocați accesul crawlerelor pe site-ul dvs.
Prin stabilirea unei liste de crawler, veți ști ce crawler-uri sunt cele bune de urmărit. Apoi, puteți să le curățați de pește și să le adăugați la lista dvs. blocată.
Cum să blocați crawlerele web rău intenționate
Cu lista de crawler-uri în mână, veți putea identifica ce roboți doriți să-i aprobați și pe care trebuie să îi blocați.
Primul pas este să parcurgeți lista de crawler și să definiți agentul utilizator și șirul complet de agent care este asociat cu fiecare crawler, precum și adresa IP specifică a acestuia. Aceștia sunt factori cheie de identificare care sunt asociați fiecărui bot.
Cu agentul utilizator și adresa IP, le puteți potrivi în înregistrările site-ului dvs. printr-o căutare DNS sau potrivire IP. Dacă nu se potrivesc exact, este posibil să aveți un bot rău intenționat care încearcă să se prezinte drept cel real.
Apoi, puteți bloca impostorul ajustând permisiunile folosind eticheta de site robots.txt .
rezumat
Crawlerele web sunt utile pentru motoarele de căutare și importante pentru a înțelege agenții de marketing.
Asigurarea faptului că site-ul dvs. este accesat cu crawlere corect de către crawlerele potrivite este importantă pentru succesul afacerii dvs. Păstrând o listă de crawler, puteți ști la care să aveți grijă când apar în jurnalul site-ului dvs.
Pe măsură ce urmați recomandările de la crawlerele comerciale și îmbunătățiți conținutul și viteza site-ului dvs., veți facilita accesul crawlerilor pe site-ul dvs. și veți indexa informațiile potrivite pentru motoarele de căutare și consumatorii care îl caută.