
JavaScriptでエラーを処理するための決定的なガイド
公開: 2022-01-24マーフィーの法則は、うまくいかないことは何でも最終的にはうまくいかないと述べています。 これは、プログラミングの世界ではあまりにもうまく適用されます。 アプリケーションを作成する場合、バグやその他の問題が発生する可能性があります。 JavaScriptのエラーは、そのような一般的な問題の1つです。
ソフトウェア製品の成功は、その作成者がユーザーを傷つける前にこれらの問題をどれだけうまく解決できるかにかかっています。 そして、JavaScriptは、すべてのプログラミング言語の中で、平均的なエラー処理設計で有名です。
JavaScriptアプリケーションを構築している場合、ある時点または別の時点でデータ型を台無しにする可能性が高くなります。 そうでない場合は、 undefinedをnullに置き換えるか、トリプルイコール演算子( === )をダブルイコール演算子( == )に置き換えることになります。
間違いを犯すのは人間だけです。 これが、JavaScriptでのエラー処理について知っておく必要のあるすべてを紹介する理由です。
この記事では、JavaScriptの基本的なエラーについて説明し、発生する可能性のあるさまざまなエラーについて説明します。 次に、これらのエラーを特定して修正する方法を学習します。 実稼働環境でエラーを効果的に処理するためのヒントもいくつかあります。
それ以上の苦労なしに、始めましょう!
JavaScriptエラーとは何ですか?
プログラミングのエラーとは、プログラムが正常に機能しない状況を指します。 これは、存在しないファイルを開こうとしたり、ネットワーク接続がないときにWebベースのAPIエンドポイントにアクセスしたりする場合など、プログラムが手元のジョブの処理方法を知らない場合に発生する可能性があります。
これらの状況は、プログラムをプッシュしてユーザーにエラーをスローし、続行する方法がわからないことを示します。 プログラムは、エラーについて可能な限り多くの情報を収集し、先に進むことができないことを報告します。
インテリジェントなプログラマーは、ユーザーが「404」などの技術的なエラーメッセージを個別に把握する必要がないように、これらのシナリオを予測してカバーしようとします。 代わりに、「ページが見つかりませんでした」というはるかにわかりやすいメッセージが表示されます。
JavaScriptのエラーは、プログラミングエラーが発生するたびに表示されるオブジェクトです。 これらのオブジェクトには、エラーのタイプ、エラーの原因となったステートメント、およびエラーが発生したときのスタックトレースに関する十分な情報が含まれています。 JavaScriptを使用すると、プログラマーはカスタムエラーを作成して、問題をデバッグするときに追加情報を提供することもできます。
エラーのプロパティ
JavaScriptエラーの定義が明確になったので、今度は詳細を詳しく見ていきましょう。
JavaScriptのエラーには、エラーの原因と影響を理解するのに役立つ特定の標準プロパティとカスタムプロパティがあります。 デフォルトでは、JavaScriptのエラーには次の3つのプロパティが含まれています。
- メッセージ:エラーメッセージを伝える文字列値
- 名前:発生したエラーのタイプ(次のセクションでこれについて詳しく説明します)
- stack :エラーが発生したときに実行されたコードのスタックトレース。
さらに、エラーには、エラーをより適切に説明するために、columnNumber、lineNumber、fileNameなどのプロパティを含めることもできます。 ただし、これらのプロパティは標準ではなく、JavaScriptアプリケーションから生成されたすべてのエラーオブジェクトに存在する場合と存在しない場合があります。
スタックトレースを理解する
スタックトレースは、例外や警告などのイベントが発生したときにプログラムが実行されたメソッド呼び出しのリストです。 これは、例外を伴うサンプルスタックトレースのようになります。
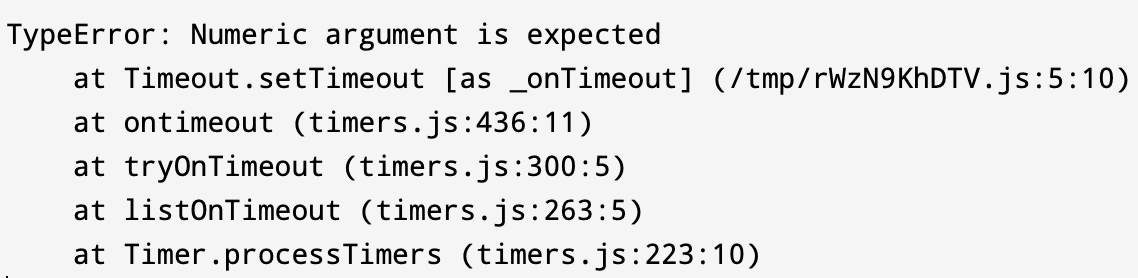
ご覧のとおり、エラー名とメッセージを出力することから始まり、その後に呼び出されていたメソッドのリストが続きます。 各メソッド呼び出しは、そのソースコードの場所とそれが呼び出された行を示します。 このデータを使用して、コードベースをナビゲートし、エラーの原因となっているコードを特定できます。
このメソッドのリストは、積み重ねられた形で配置されています。 これは、例外が最初にスローされた場所と、スタックされたメソッド呼び出しを介して例外がどのように伝播したかを示しています。 例外のキャッチを実装しても、例外がスタック全体に伝播してプログラムがクラッシュすることはありません。 ただし、一部のシナリオでは、プログラムを意図的にクラッシュさせるために、致命的なエラーをキャッチしないままにしておくことをお勧めします。
エラーと例外
ほとんどの人は通常、エラーと例外を同じものと見なします。 ただし、それらの間のわずかではあるが根本的な違いに注意することが不可欠です。
これをよりよく理解するために、簡単な例を見てみましょう。 JavaScriptでエラーを定義する方法は次のとおりです。
const wrongTypeError = TypeError("Wrong type found, expected character") そして、これがwrongTypeErrorオブジェクトが例外になる方法です。
throw wrongTypeErrorただし、ほとんどの人は、エラーオブジェクトをスローするときにエラーオブジェクトを定義する省略形を使用する傾向があります。
throw TypeError("Wrong type found, expected character")これは標準的な方法です。 ただし、これが、開発者が例外とエラーを混同する傾向がある理由の1つです。 したがって、速記を使用して作業を迅速に行う場合でも、基本を知ることは非常に重要です。
JavaScriptのエラーの種類
JavaScriptにはさまざまな定義済みのエラータイプがあります。 これらは、プログラマーがアプリケーションでエラーを明示的に処理しない場合は常に、JavaScriptランタイムによって自動的に選択および定義されます。
このセクションでは、JavaScriptで最も一般的なタイプのエラーのいくつかを説明し、それらがいつ、なぜ発生するのかを理解します。
RangeError
RangeErrorは、変数がその有効な値の範囲外の値で設定された場合にスローされます。 これは通常、関数に引数として値を渡すときに発生し、指定された値は関数のパラメーターの範囲内にありません。 引数が正しい値を渡すために可能な値の範囲を知る必要があるため、十分に文書化されていないサードパーティのライブラリを使用する場合、修正が難しい場合があります。
RangeErrorが発生する一般的なシナリオのいくつかは次のとおりです。
- Arrayコンストラクターを介して不正な長さの配列を作成しようとしています。
-
toExponential()、toPrecision()、toFixed()などの数値メソッドに不正な値を渡す normalize()などの文字列関数に不正な値を渡す。
ReferenceError
ReferenceErrorは、コード内の変数の参照に問題がある場合に発生します。 変数を使用する前に変数の値を定義するのを忘れたか、コードでアクセスできない変数を使用しようとしている可能性があります。 いずれにせよ、スタックトレースを調べることで、障害のある変数参照を見つけて修正するための十分な情報が得られます。
ReferenceErrorsが発生する一般的な理由のいくつかは次のとおりです。
- 変数名にタイプミスをする。
- スコープ外のブロックスコープ変数にアクセスしようとしています。
- ロードされる前に、外部ライブラリ(jQueryの$など)からグローバル変数を参照します。
構文エラー
これらのエラーは、コードの構文にエラーがあることを示しているため、最も簡単に修正できます。 JavaScriptはコンパイルされるのではなく解釈されるスクリプト言語であるため、これらはアプリがエラーを含むスクリプトを実行するときにスローされます。 コンパイルされた言語の場合、そのようなエラーはコンパイル中に識別されます。 したがって、アプリのバイナリは、これらが修正されるまで作成されません。
SyntaxErrorsが発生する一般的な理由のいくつかは次のとおりです。
- 引用符がありません
- 閉じ括弧がありません
- 中括弧または他の文字の不適切な配置
IDEでリンティングツールを使用して、ブラウザに到達する前にそのようなエラーを特定することをお勧めします。
TypeError
TypeErrorは、JavaScriptアプリで最も一般的なエラーの1つです。 このエラーは、特定の期待されるタイプの値が見つからない場合に発生します。 それが発生する一般的なケースのいくつかは次のとおりです。
- メソッドではないオブジェクトを呼び出す。
- nullまたは未定義のオブジェクトのプロパティにアクセスしようとしています
- 文字列を数値として扱う、またはその逆。
TypeErrorが発生する可能性は他にもたくさんあります。 後でいくつかの有名なインスタンスを見て、それらを修正する方法を学びます。
内部エラー
InternalErrorタイプは、JavaScriptランタイムエンジンで例外が発生した場合に使用されます。 コードに問題があることを示している場合と示していない場合があります。
多くの場合、InternalErrorは次の2つのシナリオでのみ発生します。
- JavaScriptランタイムのパッチまたはアップデートに、例外をスローするバグが含まれている場合(これは非常にまれにしか発生しません)
- コードにJavaScriptエンジンに対して大きすぎるエンティティが含まれている場合(たとえば、スイッチケースが多すぎる、配列初期化子が大きすぎる、再帰が多すぎる)
このエラーを解決するための最も適切なアプローチは、エラーメッセージを介して原因を特定し、可能であればアプリロジックを再構築して、JavaScriptエンジンのワークロードの突然の急増を排除することです。
URIError
URIErrorは、 decodeURIComponentなどのグローバルURI処理関数が不正に使用された場合に発生します。 これは通常、メソッド呼び出しに渡されたパラメーターがURI標準に準拠していないため、メソッドによって適切に解析されなかったことを示します。
これらのエラーの診断は、奇形の引数を調べるだけでよいため、通常は簡単です。
EvalError
EvalErrorは、 eval()関数呼び出しでエラーが発生したときに発生します。 eval()関数は、文字列に格納されたJavaScriptコードを実行するために使用されます。 ただし、セキュリティの問題によりeval()関数の使用は強く推奨されておらず、現在のECMAScript仕様ではEvalErrorクラスがスローされなくなったため、このエラータイプは、レガシーJavaScriptコードとの下位互換性を維持するためだけに存在します。
古いバージョンのJavaScriptで作業している場合は、このエラーが発生する可能性があります。 いずれの場合も、 eval()関数呼び出しで実行されたコードで例外がないか調べるのが最善です。
カスタムエラータイプの作成
JavaScriptは、ほとんどのシナリオをカバーする適切なエラータイプクラスのリストを提供しますが、リストが要件を満たさない場合は、いつでも新しいエラータイプを作成できます。 この柔軟性の基盤は、JavaScriptを使用するとthrowコマンドを使用して文字通り何でもスローできるという事実にあります。
したがって、技術的には、これらのステートメントは完全に合法です。
throw 8 throw "An error occurred" ただし、プリミティブデータ型をスローしても、その型、名前、付随するスタックトレースなど、エラーに関する詳細は提供されません。 これを修正し、エラー処理プロセスを標準化するために、 Errorクラスが提供されています。 また、例外をスローするときにプリミティブデータ型を使用することもお勧めしません。
Errorクラスを拡張して、カスタムエラークラスを作成できます。 これを行う方法の基本的な例を次に示します。
class ValidationError extends Error { constructor(message) { super(message); this.name = "ValidationError"; } }そして、あなたはそれを次のように使うことができます:
throw ValidationError("Property not found: name") そして、 instanceofキーワードを使用してそれを識別できます。
try { validateForm() // code that throws a ValidationError } catch (e) { if (e instanceof ValidationError) // do something else // do something else }JavaScriptで最も一般的なエラートップ10
一般的なエラーの種類とカスタムエラーの作成方法を理解したところで、JavaScriptコードを作成するときに直面する最も一般的なエラーのいくつかを見てみましょう。
1.キャッチされていないRangeError
このエラーは、いくつかのさまざまなシナリオでGoogleChromeで発生します。 まず、再帰関数を呼び出しても終了しない場合に発生する可能性があります。 これは、Chromeデベロッパーコンソールで自分で確認できます。
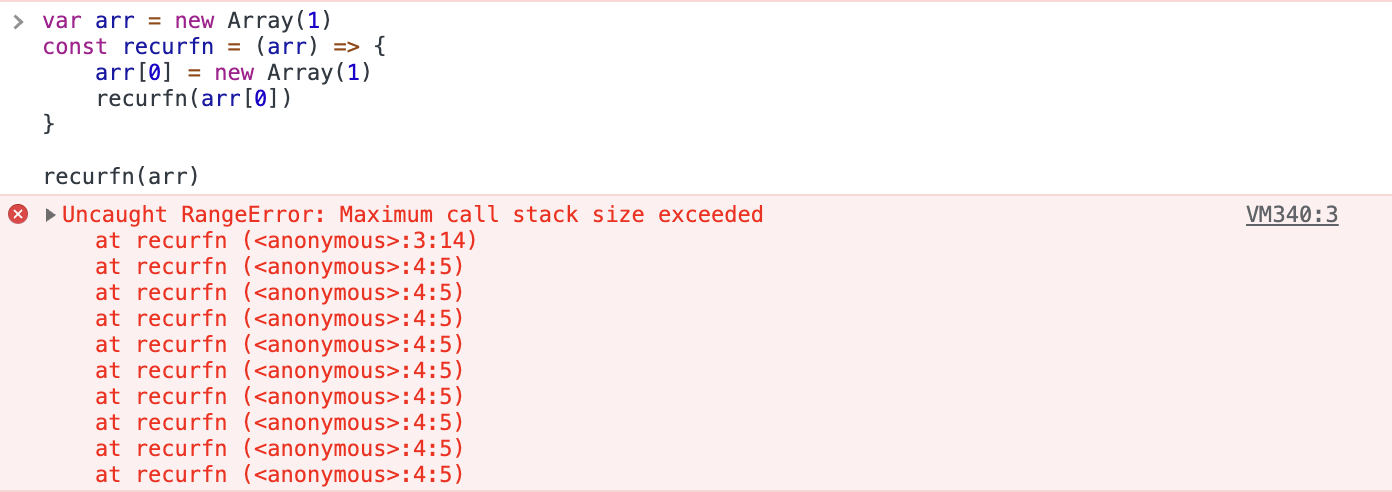
したがって、このようなエラーを解決するには、再帰関数の境界ケースを正しく定義するようにしてください。 このエラーが発生するもう1つの理由は、関数のパラメーターの範囲外の値を渡した場合です。 次に例を示します。

エラーメッセージは通常、コードの何が問題になっているのかを示します。 変更を加えると、解決されます。

2.キャッチされていないTypeError:プロパティを設定できません
このエラーは、未定義の参照にプロパティを設定した場合に発生します。 このコードで問題を再現できます。
var list list.count = 0受け取る出力は次のとおりです。

このエラーを修正するには、プロパティにアクセスする前に、参照を値で初期化します。 修正すると次のようになります。

3.キャッチされていないTypeError:プロパティを読み取れません
これは、JavaScriptで最も頻繁に発生するエラーの1つです。 このエラーは、プロパティを読み取ろうとしたとき、または未定義のオブジェクトで関数を呼び出そうとしたときに発生します。 Chromeデベロッパーコンソールで次のコードを実行すると、非常に簡単に再現できます。
var func func.call()出力は次のとおりです。

未定義のオブジェクトは、このエラーの多くの考えられる原因の1つです。 この問題のもう1つの顕著な原因は、UIのレンダリング中の状態の不適切な初期化である可能性があります。 Reactアプリケーションの実際の例を次に示します。
import React, { useState, useEffect } from "react"; const CardsList = () => { const [state, setState] = useState(); useEffect(() => { setTimeout(() => setState({ items: ["Card 1", "Card 2"] }), 2000); }, []); return ( <> {state.items.map((item) => ( <li key={item}>{item}</li> ))} </> ); }; export default CardsList;アプリは空の状態のコンテナーで開始し、2秒の遅延後にいくつかのアイテムが提供されます。 遅延は、ネットワーク呼び出しを模倣するために設定されます。 ネットワークが超高速であっても、コンポーネントが少なくとも1回レンダリングされるため、わずかな遅延が発生します。 このアプリを実行しようとすると、次のエラーが発生します。
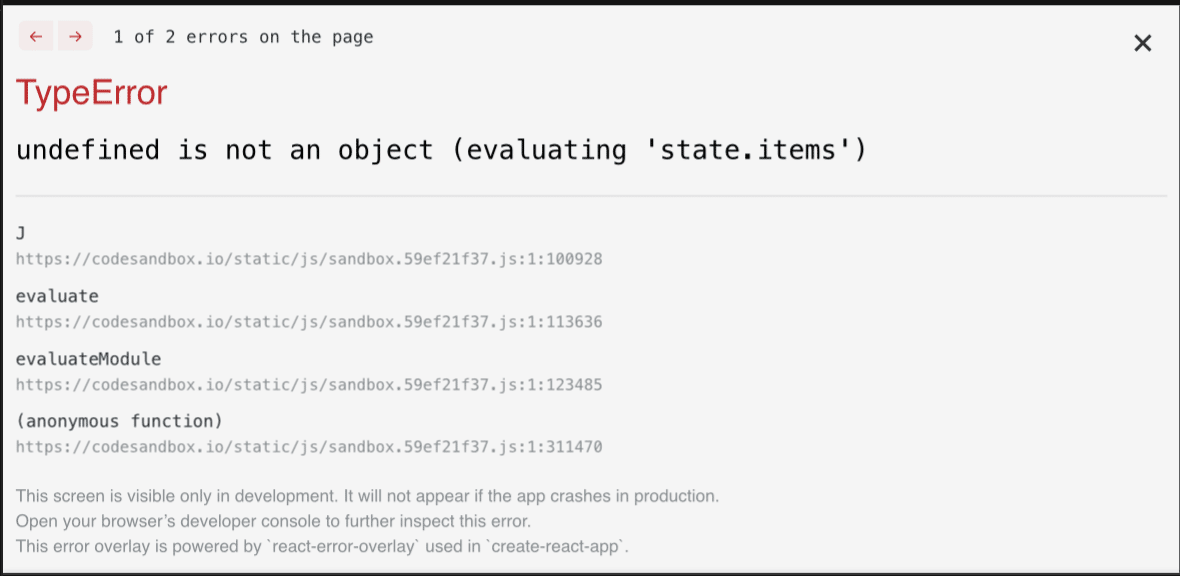
これは、レンダリング時に、状態コンテナが未定義であるためです。 したがって、プロパティitemsは存在しません。 このエラーの修正は簡単です。 状態コンテナに初期デフォルト値を指定する必要があります。
// ... const [state, setState] = useState({items: []}); // ...これで、設定された遅延の後、アプリは同様の出力を表示します。

コードの正確な修正は異なる場合がありますが、ここでの本質は、変数を使用する前に常に変数を適切に初期化することです。
4. TypeError:'undefined'はオブジェクトではありません
このエラーは、未定義のオブジェクトのプロパティにアクセスしたり、メソッドを呼び出そうとしたときにSafariで発生します。 上から同じコードを実行して、エラーを自分で再現できます。

このエラーの解決策も同じです。変数を正しく初期化し、プロパティまたはメソッドにアクセスするときに変数が未定義になっていないことを確認してください。
5. TypeError:nullはオブジェクトではありません
これも前のエラーと同様です。 これはSafariで発生し、2つのエラーの唯一の違いは、プロパティまたはメソッドにアクセスしているオブジェクトがundefinedではなくnullの場合にスローされることです。 次のコードを実行することで、これを再現できます。
var func = null func.call()受け取る出力は次のとおりです。

nullは変数に明示的に設定され、JavaScriptによって自動的に割り当てられない値であるため。 このエラーは、自分でnullを設定した変数にアクセスしようとしている場合にのみ発生する可能性があります。 したがって、コードを再検討して、作成したロジックが正しいかどうかを確認する必要があります。
6. TypeError:プロパティ'length'を読み取れません
このエラーは、Chromeでnullまたはundefinedのオブジェクトの長さを読み取ろうとしたときに発生します。 この問題の原因は前の問題と同様ですが、リストの処理中に非常に頻繁に発生します。 したがって、それは特別な言及に値します。 問題を再現する方法は次のとおりです。
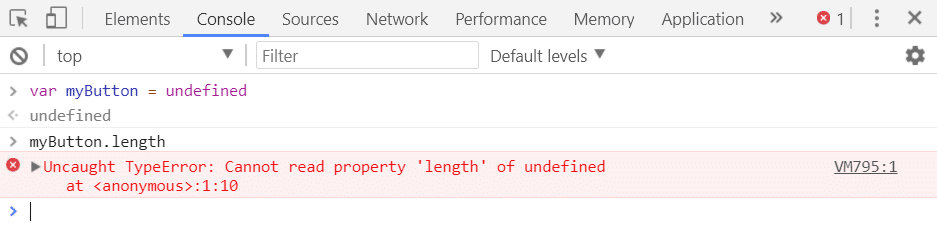
ただし、Chromeの新しいバージョンでは、このエラーはUncaught TypeError: Cannot read properties of undefined 。 これが今の様子です:

繰り返しますが、修正は、アクセスしようとしている長さがnullに設定されていないオブジェクトが存在することを確認することです。
7. TypeError:'undefined'は関数ではありません
このエラーは、スクリプトに存在しないメソッドを呼び出そうとした場合、または存在するが呼び出し元のコンテキストで参照できない場合に発生します。 このエラーは通常GoogleChromeで発生し、エラーをスローするコード行を確認することで解決できます。 タイプミスを見つけた場合は、それを修正して、問題が解決するかどうかを確認します。
コードで自己参照キーワードthisを使用した場合、これがコンテキストに適切にバインドされていないと、 thisエラーが発生する可能性があります。 次のコードを検討してください。
function showAlert() { alert("message here") } document.addEventListener("click", () => { this.showAlert(); }) 上記のコードを実行すると、説明したエラーがスローされます。 これは、イベントリスナーとして渡された無名関数がdocumentのコンテキストで実行されているために発生します。
対照的に、関数showAlertは、 windowのコンテキストで定義されます。
これを解決するには、 bind()メソッドで関数をバインドして、関数への適切な参照を渡す必要があります。
document.addEventListener("click", this.showAlert.bind(this))8. ReferenceError:イベントが定義されていません
このエラーは、呼び出し元のスコープで定義されていない参照にアクセスしようとしたときに発生します。 これは通常、イベントを処理するときに発生します。これは、イベントがコールバック関数でeventと呼ばれる参照を提供することが多いためです。 このエラーは、関数のパラメーターでイベント引数を定義するのを忘れたり、スペルを間違えたりした場合に発生する可能性があります。
このエラーは、InternetExplorerまたはGoogleChromeでは発生しない可能性があります(IEはグローバルイベント変数を提供し、Chromeはイベント変数をハンドラーに自動的にアタッチするため)が、Firefoxでは発生する可能性があります。 したがって、このような小さな間違いに注意することをお勧めします。
9. TypeError:定数変数への割り当て
これは不注意から生じるエラーです。 定数変数に新しい値を割り当てようとすると、次のような結果になります。

今のところ修正するのは簡単なようですが、そのような変数宣言が何百もあり、そのうちの1つがletではなくconstとして誤って定義されていることを想像してみてください。 PHPのような他のスクリプト言語とは異なり、JavaScriptで定数と変数を宣言するスタイルには最小限の違いがあります。 したがって、このエラーが発生した場合は、まず宣言を確認することをお勧めします。 上記の参照が定数であることを忘れて変数として使用した場合にも、このエラーが発生する可能性があります。 これは、アプリのロジックに不注意または欠陥があることを示しています。 この問題を修正するときは、必ずこれを確認してください。
10.(不明):スクリプトエラー
スクリプトエラーは、サードパーティのスクリプトがブラウザにエラーを送信したときに発生します。 サードパーティのスクリプトはアプリとは異なるドメインに属しているため、このエラーの後に(不明)が続きます。 ブラウザは、サードパーティのスクリプトから機密情報が漏洩するのを防ぐために、他の詳細を非表示にします。

完全な詳細を知らなければ、このエラーを解決することはできません。 エラーに関する詳細情報を取得するためにできることは次のとおりです。
- スクリプトタグに
crossorigin属性を追加します。 - スクリプトをホストしているサーバーに正しい
Access-Control-Allow-Originヘッダーを設定します。 - [オプション]スクリプトをホストしているサーバーにアクセスできない場合は、プロキシを使用してリクエストをサーバーに中継し、正しいヘッダーを使用してクライアントに戻すことを検討できます。
エラーの詳細にアクセスできるようになったら、問題の修正に取り掛かることができます。これは、おそらくサードパーティのライブラリまたはネットワークのいずれかで発生します。
JavaScriptのエラーを識別して防止する方法
上記のエラーはJavaScriptで最も一般的で頻繁に発生しますが、いくつかの例に頼るだけでは十分ではありません。 JavaScriptアプリケーションの開発中に、JavaScriptアプリケーションのあらゆるタイプのエラーを検出して防止する方法を理解することが重要です。 JavaScriptでエラーを処理する方法は次のとおりです。
エラーを手動でスローしてキャッチ
手動またはランタイムによってスローされたエラーを処理する最も基本的な方法は、エラーをキャッチすることです。 他のほとんどの言語と同様に、JavaScriptはエラーを処理するための一連のキーワードを提供します。 JavaScriptアプリでエラーを処理する前に、それぞれを深く理解することが重要です。
投げる
セットの最初で最も基本的なキーワードはthrowです。 明らかなように、throwキーワードは、JavaScriptランタイムで手動で例外を作成するためのエラーをスローするために使用されます。 これについては、この記事の前半ですでに説明しました。このキーワードの重要性の要点は次のとおりです。
- 数字、文字列、
Errorオブジェクトなど、何でもthrowできます。 - ただし、文字列や数値などのプリミティブデータ型はエラーに関するデバッグ情報を伝達しないため、これらをスローすることはお勧めしません。
- 例:
throw TypeError("Please provide a string")
試す
tryキーワードは、コードのブロックが例外をスローする可能性があることを示すために使用されます。 その構文は次のとおりです。
try { // error-prone code here } エラーを効果的に処理するには、 catchブロックが常にtryブロックの後に続く必要があることに注意することが重要です。
キャッチ
catchキーワードは、catchブロックを作成するために使用されます。 このコードブロックは、後続のtryブロックがキャッチするエラーを処理する役割を果たします。 その構文は次のとおりです。
catch (exception) { // code to handle the exception here } そして、これは、 tryブロックとcatchブロックを一緒に実装する方法です。
try { // business logic code } catch (exception) { // error handling code } C ++やJavaとは異なり、JavaScriptのtryブロックに複数のcatchブロックを追加することはできません。 これは、これを行うことができないことを意味します。
try { // business logic code } catch (exception) { if (exception instanceof TypeError) { // do something } } catch (exception) { if (exception instanceof RangeError) { // do something } } 代わりに、単一のcatchブロック内でif...elseステートメントまたはswitchcaseステートメントを使用して、考えられるすべてのエラーケースを処理できます。 次のようになります。
try { // business logic code } catch (exception) { if (exception instanceof TypeError) { // do something } else if (exception instanceof RangeError) { // do something else } }ついに
finallyキーワードは、エラーが処理された後に実行されるコードブロックを定義するために使用されます。 このブロックは、tryブロックとcatchブロックの後に実行されます。
また、finallyブロックは、他の2つのブロックの結果に関係なく実行されます。 これは、catchブロックがエラーを完全に処理できない場合や、catchブロックでエラーがスローされた場合でも、プログラムがクラッシュする前に、インタープリターがfinallyブロックのコードを実行することを意味します。
有効と見なされるには、JavaScriptのtryブロックの後に、catchまたはfinallyブロックが続く必要があります。 これらがないと、インタプリタはSyntaxErrorを発生させます。 したがって、エラーを処理するときは、少なくともいずれかのtryブロックを必ず実行してください。
onerror()メソッドを使用してエラーをグローバルに処理する
onerror()メソッドは、すべてのHTML要素で使用可能であり、それらで発生する可能性のあるエラーを処理します。 たとえば、 imgタグがURLが指定されている画像を見つけられない場合、そのonerrorメソッドを起動して、ユーザーがエラーを処理できるようにします。
通常、 imgタグをフォールバックするonerror呼び出しで、別の画像URLを指定します。 これは、JavaScriptを介してそれを行う方法です。
const image = document.querySelector("img") image.onerror = (event) => { console.log("Error occurred: " + event) }ただし、この機能を使用して、アプリのグローバルエラー処理メカニズムを作成できます。 これがあなたがそれをすることができる方法です:
window.onerror = (event) => { console.log("Error occurred: " + event) } このイベントハンドラーを使用すると、コード内にある複数のtry...catchブロックを取り除き、イベント処理と同様にアプリのエラー処理を一元化できます。 複数のエラーハンドラーをウィンドウにアタッチして、SOLID設計原則からの単一責任原則を維持できます。 インタプリタは、適切なハンドラに到達するまで、すべてのハンドラを循環します。
コールバックを介してエラーを渡す
単純で線形関数を使用するとエラー処理を単純に保つことができますが、コールバックは問題を複雑にする可能性があります。
次のコードについて考えてみます。
競争力を高めるホスティングソリューションが必要ですか? Kinstaは、信じられないほどの速度、最先端のセキュリティ、および自動スケーリングであなたをカバーします。 私たちの計画をチェックしてください
const calculateCube = (number, callback) => { setTimeout(() => { const cube = number * number * number callback(cube) }, 1000) } const callback = result => console.log(result) calculateCube(4, callback)上記の関数は、関数が操作を処理するのに時間がかかり、後でコールバックを使用して結果を返す非同期条件を示しています。
関数呼び出しで4ではなく文字列を入力しようとすると、結果としてNaNが取得されます。
これは適切に処理する必要があります。 方法は次のとおりです。
const calculateCube = (number, callback) => { setTimeout(() => { if (typeof number !== "number") throw new Error("Numeric argument is expected") const cube = number * number * number callback(cube) }, 1000) } const callback = result => console.log(result) try { calculateCube(4, callback) } catch (e) { console.log(e) }これは問題を理想的に解決するはずです。 ただし、関数呼び出しに文字列を渡そうとすると、次のようになります。

関数の呼び出し中にtry-catchブロックを実装した場合でも、エラーがキャッチされないと表示されます。 タイムアウト遅延のため、catchブロックが実行された後にエラーがスローされます。
これは、予期しない遅延が発生するネットワークコールですぐに発生する可能性があります。アプリの開発中に、このようなケースをカバーする必要があります。
コールバックでエラーを適切に処理する方法は次のとおりです。
const calculateCube = (number, callback) => { setTimeout(() => { if (typeof number !== "number") { callback(new TypeError("Numeric argument is expected")) return } const cube = number * number * number callback(null, cube) }, 2000) } const callback = (error, result) => { if (error !== null) { console.log(error) return } console.log(result) } try { calculateCube('hey', callback) } catch (e) { console.log(e) }これで、コンソールでの出力は次のようになります。

これは、エラーが適切に処理されたことを示しています。
Promiseのエラーを処理する
ほとんどの人は、非同期アクティビティを処理するための約束を好む傾向があります。 Promiseには別の利点があります。Promiseが拒否されてもスクリプトは終了しません。 ただし、promiseのエラーを処理するには、catchブロックを実装する必要があります。 これをよりよく理解するために、Promisesを使用してcalculateCube()関数を書き直してみましょう。
const delay = ms => new Promise(res => setTimeout(res, ms)); const calculateCube = async (number) => { if (typeof number !== "number") throw Error("Numeric argument is expected") await delay(5000) const cube = number * number * number return cube } try { calculateCube(4).then(r => console.log(r)) } catch (e) { console.log(e) } 前のコードからのタイムアウトは、理解のためにdelay関数に分離されています。 4ではなく文字列を入力しようとすると、次のような出力が得られます。

繰り返しますが、これは、他のすべてが実行を完了した後にPromiseがエラーをスローするためです。 この問題の解決策は簡単です。 次のように、 catch()呼び出しをpromiseチェーンに追加するだけです。
calculateCube("hey") .then(r => console.log(r)) .catch(e => console.log(e))これで、出力は次のようになります。

promiseを使用してエラーを処理するのがいかに簡単であるかを観察できます。 さらに、 finally()ブロックとpromise呼び出しをチェーンして、エラー処理が完了した後に実行されるコードを追加できます。
または、従来のtry-catch-finally手法を使用して、promiseのエラーを処理することもできます。 その場合のpromise呼び出しは次のようになります。
try { let result = await calculateCube("hey") console.log(result) } catch (e) { console.log(e) } finally { console.log('Finally executed") } ただし、これは非同期関数内でのみ機能します。 したがって、promiseのエラーを処理する最も好ましい方法は、 catchをチェーンし、 finallyにpromise呼び出しを行うことです。
throw / catch vs onerror()vs Callbacks vs Promises:どちらがベストですか?
4つの方法を自由に使用できるため、特定のユースケースで最も適切なものを選択する方法を知っている必要があります。 自分で決める方法は次のとおりです。
投げる/キャッチする
ほとんどの場合、この方法を使用します。 catchブロック内で発生する可能性のあるすべてのエラーの条件を実装し、tryブロックの後にメモリクリーンアップルーチンを実行する必要がある場合は、finallyブロックを含めることを忘れないでください。
ただし、try / catchブロックが多すぎると、コードの保守が困難になる可能性があります。 このような状況に陥った場合は、グローバルハンドラーまたはpromiseメソッドを使用してエラーを処理することをお勧めします。
非同期のtry/catchブロックとpromiseのcatch()のどちらを使用するかを決定するときは、非同期のtry / catchブロックを使用することをお勧めします。これにより、コードが線形になり、デバッグが容易になります。
onerror()
アプリで多くのエラーを処理する必要があることがわかっている場合は、 onerror()メソッドを使用することをお勧めします。エラーは、コードベース全体に分散している可能性があります。 onerrorメソッドを使用すると、アプリケーションによって処理される別のイベントであるかのようにエラーを処理できます。 複数のエラーハンドラーを定義して、初期レンダリング時にアプリのウィンドウにアタッチできます。
ただし、 onerror()メソッドは、エラーの範囲が狭い小規模なプロジェクトで設定するのが不必要に難しい場合があることも覚えておく必要があります。 アプリがあまり多くのエラーをスローしないことが確実な場合は、従来のthrow/catchメソッドが最適です。
コールバックと約束
コールバックとPromiseのエラー処理は、コードの設計と構造によって異なります。 ただし、コードを作成する前にこれら2つから選択する場合は、promiseを使用するのが最善です。
これは、promiseには、エラーを簡単に処理するために、 catch() )ブロックとfinally()ブロックをチェーンするための組み込み構造があるためです。 この方法は、追加の引数を定義したり、既存の引数を再利用してエラーを処理したりするよりも簡単でクリーンです。
Gitリポジトリで変更を追跡する
多くの場合、コードベースの手動ミスが原因で多くのエラーが発生します。 コードの開発またはデバッグ中に、不要な変更を加えて、コードベースに新しいエラーが表示される可能性があります。 Automated testing is a great way to keep your code in check after every change. However, it can only tell you if something's wrong. If you don't take frequent backups of your code, you'll end up wasting time trying to fix a function or a script that was working just fine before.
This is where git plays its role. With a proper commit strategy, you can use your git history as a backup system to view your code as it evolved through the development. You can easily browse through your older commits and find out the version of the function working fine before but throwing errors after an unrelated change.
You can then restore the old code or compare the two versions to determine what went wrong. Modern web development tools like GitHub Desktop or GitKraken help you to visualize these changes side by side and figure out the mistakes quickly.
A habit that can help you make fewer errors is running code reviews whenever you make a significant change to your code. If you're working in a team, you can create a pull request and have a team member review it thoroughly. This will help you use a second pair of eyes to spot out any errors that might have slipped by you.
Best Practices for Handling Errors in JavaScript
The above-mentioned methods are adequate to help you design a robust error handling approach for your next JavaScript application. However, it would be best to keep a few things in mind while implementing them to get the best out of your error-proofing. Here are some tips to help you.
1. Use Custom Errors When Handling Operational Exceptions
We introduced custom errors early in this guide to give you an idea of how to customize the error handling to your application's unique case. It's advisable to use custom errors wherever possible instead of the generic Error class as it provides more contextual information to the calling environment about the error.
On top of that, custom errors allow you to moderate how an error is displayed to the calling environment. This means that you can choose to hide specific details or display additional information about the error as and when you wish.
You can go so far as to format the error contents according to your needs. This gives you better control over how the error is interpreted and handled.
2. Do Not Swallow Any Exceptions
Even the most senior developers often make a rookie mistake — consuming exceptions levels deep down in their code.
You might come across situations where you have a piece of code that is optional to run. If it works, great; if it doesn't, you don't need to do anything about it.
In these cases, it's often tempting to put this code in a try block and attach an empty catch block to it. However, by doing this, you'll leave that piece of code open to causing any kind of error and getting away with it. This can become dangerous if you have a large codebase and many instances of such poor error management constructs.
The best way to handle exceptions is to determine a level on which all of them will be dealt and raise them until there. This level can be a controller (in an MVC architecture app) or a middleware (in a traditional server-oriented app).
This way, you'll get to know where you can find all the errors occurring in your app and choose how to resolve them, even if it means not doing anything about them.
3. Use a Centralized Strategy for Logs and Error Alerts
Logging an error is often an integral part of handling it. Those who fail to develop a centralized strategy for logging errors may miss out on valuable information about their app's usage.
An app's event logs can help you figure out crucial data about errors and help to debug them quickly. If you have proper alerting mechanisms set up in your app, you can know when an error occurs in your app before it reaches a large section of your user base.
It's advisable to use a pre-built logger or create one to suit your needs. You can configure this logger to handle errors based on their levels (warning, debug, info, etc.), and some loggers even go so far as to send logs to remote logging servers immediately. This way, you can watch how your application's logic performs with active users.
4. Notify Users About Errors Appropriately
Another good point to keep in mind while defining your error handling strategy is to keep the user in mind.
All errors that interfere with the normal functioning of your app must present a visible alert to the user to notify them that something went wrong so the user can try to work out a solution. If you know a quick fix for the error, such as retrying an operation or logging out and logging back in, make sure to mention it in the alert to help fix the user experience in real-time.
In the case of errors that don't cause any interference with the everyday user experience, you can consider suppressing the alert and logging the error to a remote server for resolving later.
5. Implement a Middleware (Node.js)
The Node.js environment supports middlewares to add functionalities to server applications. You can use this feature to create an error-handling middleware for your server.
The most significant benefit of using middleware is that all of your errors are handled centrally in one place. You can choose to enable/disable this setup for testing purposes easily.
Here's how you can create a basic middleware:
const logError = err => { console.log("ERROR: " + String(err)) } const errorLoggerMiddleware = (err, req, res, next) => { logError(err) next(err) } const returnErrorMiddleware = (err, req, res, next) => { res.status(err.statusCode || 500) .send(err.message) } module.exports = { logError, errorLoggerMiddleware, returnErrorMiddleware }次に、次のようにアプリでこのミドルウェアを使用できます。
const { errorLoggerMiddleware, returnErrorMiddleware } = require('./errorMiddleware') app.use(errorLoggerMiddleware) app.use(returnErrorMiddleware)ミドルウェア内でカスタムロジックを定義して、エラーを適切に処理できるようになりました。 コードベース全体に個別のエラー処理構造を実装することを心配する必要はもうありません。
6.アプリを再起動してプログラマーエラーを処理する(Node.js)
Node.jsアプリでプログラマーエラーが発生した場合、必ずしも例外をスローしてアプリを閉じようとはしません。 このようなエラーには、CPU消費量の多さ、メモリの肥大化、メモリリークなど、プログラマーのミスから生じる問題が含まれる場合があります。 これらを処理する最良の方法は、Node.jsクラスターモードまたはPM2などの独自のツールを介してアプリをクラッシュさせてアプリを正常に再起動することです。 これにより、ユーザーの操作時にアプリがクラッシュせず、ひどいユーザーエクスペリエンスが提供されます。
7.キャッチされていないすべての例外をキャッチする(Node.js)
アプリで発生する可能性のあるすべてのエラーをカバーしたことを確信することはできません。 したがって、アプリからキャッチされなかったすべての例外をキャッチするためのフォールバック戦略を実装することが不可欠です。
これを行う方法は次のとおりです。
process.on('uncaughtException', error => { console.log("ERROR: " + String(error)) // other handling mechanisms })発生したエラーが標準例外なのかカスタム操作エラーなのかを特定することもできます。 結果に基づいて、プロセスを終了して再開し、予期しない動作を回避できます。
8.未処理のPromise拒否をすべてキャッチします(Node.js)
考えられるすべての例外をカバーできないのと同様に、考えられるすべての約束の拒否の処理を見逃す可能性が高くなります。 ただし、例外とは異なり、Promiseの拒否はエラーをスローしません。
そのため、拒否された重要な約束が警告としてすり抜けて、予期しない動作に遭遇する可能性にアプリを開いたままにする可能性があります。 したがって、Promiseの拒否を処理するためのフォールバックメカニズムを実装することが重要です。
これを行う方法は次のとおりです。
const promiseRejectionCallback = error => { console.log("PROMISE REJECTED: " + String(error)) } process.on('unhandledRejection', callback) 概要
他のプログラミング言語と同様に、JavaScriptではエラーが非常に頻繁に発生します。 場合によっては、ユーザーに正しい応答を示すために、意図的にエラーをスローする必要があります。 したがって、それらの構造とタイプを理解することは非常に重要です。
さらに、エラーによるアプリケーションの停止を特定して防止するための適切なツールと手法を備えている必要があります。
ほとんどの場合、すべてのタイプのJavaScriptアプリケーションでは、慎重に実行してエラーを処理するための確実な戦略で十分です。
まだ解決できないJavaScriptエラーは他にありますか? JSエラーを建設的に処理するためのテクニックはありますか? 以下のコメントでお知らせください!