
大規模なeコマースWebサイトの重複コンテンツを処理する方法
公開: 2021-12-02
Googleは同じ内容のURLにペナルティを科します。 これは、eコマースWebサイトや、さまざまなWebサイトで販売されている製品の同じ説明をメーカーが保持することを好む一部の旅行Webサイトで最もよく発生します。
これは、eコマースWebサイトが現在直面している最大の課題です。 重複するコンテンツとは、SEOランキングとウェブトラフィック、そして最も重要なこととしてウェブサイトの評判を落とす可能性のあるあらゆる種類の盗用、コンテンツのスクレイピング、操作を意味します。
重複するコンテンツは、外部または内部の場合があります。 あるeコマースWebサイトのコンテンツが別のeコマースWebサイトのコンテンツと同じである場合、それらは外部重複コンテンツと呼ばれます。
一方、内部の重複コンテンツはeコマースWebサイト自体にあり、eコマースWebサイト内の技術的な不具合や編集上の原因により発生する可能性があります。 重複するコンテンツを処理し、コンテンツが盗用されたり操作されたりしないようにする方法は次のとおりです。
一貫性の維持:

WebサイトのURLの構造に一貫性がない場合、重複したコンテンツが報告される可能性が高くなります。 重複コンテンツを処理するための最良の解決策は、URL構造を標準化し、正規タグを適切に使用することです。
wwwまたはHTTPのいずれかを使用するURLバージョンに関係なく、それらは一貫している必要があります。 ページの右隅にあるサイト設定にログインしてから、優先ドメイン名を設定するだけで、優先ドメインを設定できます。
ただし、他の不整合もURL構造に表示される場合があります。 したがって、URLの構造を単純に保つとともに、URLの構文やその他のパラメーターを正しく保つ必要もあります。
正規化:
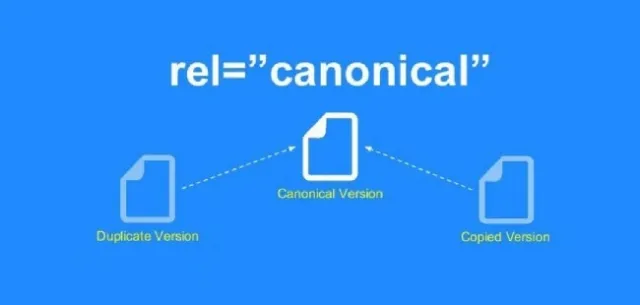
これは、重複コンテンツを処理するためのさらに別の方法です。 ユーザーがタグや商品のカテゴリで検索すると、Googleは同じ結果を表示することがよくあります。 これは、顧客が毎回同じ検索結果を取得することが多いeコマースWebサイトで最もよく発生します。
複数のウェブサイトの同じコンテンツは、検索結果に表示するURLをGoogleに混乱させます。 この問題に対処するために、Googleは、サイト所有者がコンテンツに正規タグを使用することをお勧めします。 これは、検索エンジンが正規のタグを見つけた後、元のリソースにリンクするのに役立ちます。
01リダイレクト:

URLの再構築などの適切な取り組みによって、コンテンツが重複する場合もあります。 したがって、リンクを再構築するときは、Googleが設定したガイドラインに必ず従ってください。 301リダイレクトの助けを借りて、あなたはあなたの好みについて検索エンジンに警告することができます、そしてそれは重複した内容から遠ざかる素晴らしい方法です。
検索エンジンが重複したコンテンツを含むWebページに到達した場合でも、301リダイレクトを確認すると、元のリソースページに到達できます。 重複する各ページに301のリダイレクトが含まれている場合、SEOランキングは失われません。 Webサイトの性質に応じて、301リダイレクトを設定できます。
コンテンツシンジケーション:

eコマースサイトの場合、いくつかのコンテンツがさまざまなプラットフォームで再公開されます。 このような場合、同じコンテンツが繰り返されるたびに、アンカーテキストを使用して元のサイトに戻すようにWebサイトを再公開することをお勧めします。 これは、重複コンテンツを処理するための最良の方法の1つです。

Google検索コンソールツール:

Google検索コンソールツールはウェブサイトでの設定が非常に簡単で、重複した薄いコンテンツを簡単に識別できるため、eコマースウェブサイトを最も時間のかかる作業から節約できます。 重複するコンテンツを識別するためにGoogle検索コンソールツールを使用できるいくつかの方法を以下に説明します。
HTMLの改善–重複するタイトルタグとメタディスクリプションを持つURLを簡単に指摘できます。
URLパラメータ–特定のウェブサイトへのクロールやインデックス作成の問題が存在する場合、Googleはそのような問題を簡単に特定し、即座に修正します。
検索クエリ演算子:
これは、Googleを使用して重複コンテンツを処理するためのさらに別の効果的な方法です。 以下の演算子です。
サイト: –あなたのウェブサイトからグーグルによって索引付けされたほとんどのURLを表示するグーグルオペレーターです。 これは、Googleがあなたのウェブサイトからインデックスに登録されたURLの数が多すぎるかどうかを調べるための非常に効果的なプロセスです。
Inurl: –この演算子は通常、Googleによってインデックス付けされた特定のURLパラメーターを見つけるためにサイト演算子と一緒に使用されます。 これは、Googleによってインデックス付けされた潜在的に有害なパラメータを除外するのに役立ちます。
タイトル:これらのGoogleオペレーターは、タグに特定のメタタイトルを持つGoogleによってインデックス付けされた特定のURLを表示します。 eコマースWebサイトでは、このオペレーターは、別のページのレビューも含む製品ページの重複コンテンツを識別するのに役立ちます。
盗作ツール:
これらは、Webサイトから重複コンテンツをスクレイピングするのに役立つサードパーティのツールです。 ここでは、そのような3つのツールについて説明します。
Copyscape: –このツールは、さまざまなWebサイトに含まれる編集上の重複コンテンツを識別します。 さまざまなウェブサイトのサイトマップをクロールして、そこに含まれるすべてのURLをGoogleのインデックスにある他のURLと比較して、編集コンテンツが盗用されているかどうかを確認できます。 コピーして貼り付けた製品の説明を簡単に検出できます。
悲鳴を上げるカエル: –これは非常に高度な専門機能を備えた非常に人気のあるツールです。 Webサイトに簡単にクロールし、コンテンツの重複やエラーメッセージが原因で発生する可能性のある技術的な問題を検出できます。
Siteliner: –このツールは、eコマースWebサイトのさまざまなWebページの内部重複コンテンツを識別します。
経験と直感
重複コンテンツの識別に役立つ上記のツールとヒントを除けば、重複コンテンツの検出に関しては、長年の専門知識と経験が間違いを犯すことはありません。 あなたがこれらの問題に取り組み続けるにつれて、あなたの心は、重複した内容があなたの目に簡単に識別されるような方法で自分自身を教え込みます。
Webの世界では、コンテンツの重複は避けられません。 これは、アイデアを再現できないため、ジャーナリストが他のいくつかの記事から記事を引用するときはいつでも、いくつかの重複したコンテンツがそれに付随するためです。
ただし、重複するコンテンツを楽しまないように対策を講じる必要があります。重複するコンテンツはWebサイトのSEOランキングを指数関数的に低下させ、その後Webトラフィックが横に流れてしまうためです。